PHP
如何生成网志信息统计图形
前几天从keso的网志链接过去后看到一篇文字“Keso博客发布时间的统计分析”,图形画得比较有意思。我考虑了一下,那个统计图(至少)有两种实现方式:普通用户的方式和程序员的方式。1
(以下的讨论以本站网志和本站网志使用的Serendipity系统为例)
一、普通用户的方式:Excel生成
首先,将网站的网志信息导出来。例如,Serendipity网志系统就有“文字导出”(Export entries)的功能,能够把全部文字导出到RSS中(XML格式)。
除了xls文件格式外,Microsoft Excel还能够读入多种文件格式,例如csv格式和XML格式。那么,就用Excel打开这个XML导出文件。2
把相关的信息在Excel中稍作处理,然后使用Excel的画图功能画图。在这个过程中,(可能)需要使用一些Excel的相关函数处理数据,例如datevalue()、left()等。
 这个方法适用于大多数(颇为)熟悉Excel使用的用户,不需要什么编程操作。右图就是使用此方法制作的本站2003年7月到现在所有的网志文字发布时间的统计信息。3
这个方法适用于大多数(颇为)熟悉Excel使用的用户,不需要什么编程操作。右图就是使用此方法制作的本站2003年7月到现在所有的网志文字发布时间的统计信息。3
二、程序员的方式:PHP生成
显然,用PHP画图需要用到用于画图的GD库,还需要相应的字体支持。
在经典的PHP函数库网站phpclasses搜索,很难发现让人满意的第三方图形类库用于画图。但其实,PHP自带的PEAR函数库就具有极强的画图功能,不需要另外找第三方函数库。
我以往极少采用PEAR写程序。前几天翻了翻,好像PEAR提供的具体使用文档很少。不管怎样,还是把如何用PEAR画图的方法简单讲一下(,免得自己以后忘了)。4
1. (至少)需要用到PEAR中的三个Image库:Image_Graph,Image_Canvas,Image_Color。下载它们并放到适当位置。
2. (一般来讲)要把PEAR所在位置加到php.ini所定义的incude_path中。
3. 需要一些TrueType的字体。“PEAR/Image/Canvas/Fonts/fontmap.txt”这个文件定义了相关的字体(文件)名字。(从网上或服务器上)找到这些字体文件,把这些字体文件放到系统某个位置。
4. 在“PEAR/Image/Canvas.php”文件中,定义常量“IMAGE_CANVAS_SYSTEM_FONT_PATH”。此常量用来指定字体文件所在位置。
 5. 参考“PEAR/Graph/docs”和“Graph/tests”下的多个画图的例子,挺简单的。这里就给两个和本文提到的离散图相关的例子(见右图):
5. 参考“PEAR/Graph/docs”和“Graph/tests”下的多个画图的例子,挺简单的。这里就给两个和本文提到的离散图相关的例子(见右图):
5.1 “PEAR/Graph/docs/examples/double_category_axis.php”。
5.2 “PEAR/Graph/docs/examples/plot_scatter.php”。
在Serendipity中,可以使用方法二开发相关的图形统计插件。Deminy觉得自己写这个太浪费时间了,就免了。相信以后肯定会有人写的。
[注1] 上面提到的文章的作者使用的是一个叫做Swiff Chart软件制作统计图。
[注2] 如果你直接用Excel打开该XML文件困难的话,可能是因为缺乏必要的XML Schema信息。这时候,综合使用Excel的mapping功能,便可以将XML中的指定数据(pubDate)导入。
[注3] 以后有时间的话我会做具体数据的具体分析。
[注4] 此处相关代码和实现方式测试于3月24日下午。
(以下的讨论以本站网志和本站网志使用的Serendipity系统为例)
一、普通用户的方式:Excel生成
首先,将网站的网志信息导出来。例如,Serendipity网志系统就有“文字导出”(Export entries)的功能,能够把全部文字导出到RSS中(XML格式)。
除了xls文件格式外,Microsoft Excel还能够读入多种文件格式,例如csv格式和XML格式。那么,就用Excel打开这个XML导出文件。2
把相关的信息在Excel中稍作处理,然后使用Excel的画图功能画图。在这个过程中,(可能)需要使用一些Excel的相关函数处理数据,例如datevalue()、left()等。
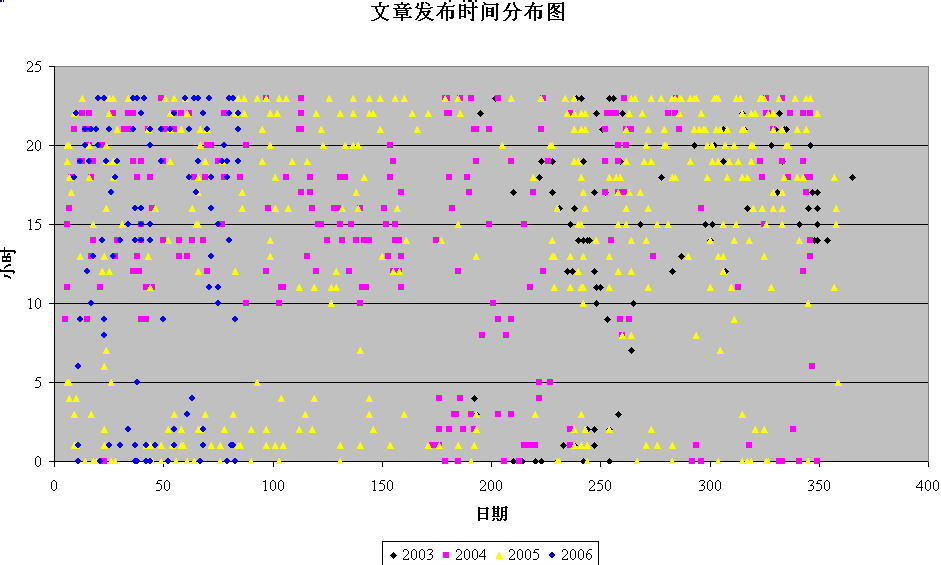 这个方法适用于大多数(颇为)熟悉Excel使用的用户,不需要什么编程操作。右图就是使用此方法制作的本站2003年7月到现在所有的网志文字发布时间的统计信息。3
这个方法适用于大多数(颇为)熟悉Excel使用的用户,不需要什么编程操作。右图就是使用此方法制作的本站2003年7月到现在所有的网志文字发布时间的统计信息。3二、程序员的方式:PHP生成
显然,用PHP画图需要用到用于画图的GD库,还需要相应的字体支持。
在经典的PHP函数库网站phpclasses搜索,很难发现让人满意的第三方图形类库用于画图。但其实,PHP自带的PEAR函数库就具有极强的画图功能,不需要另外找第三方函数库。
我以往极少采用PEAR写程序。前几天翻了翻,好像PEAR提供的具体使用文档很少。不管怎样,还是把如何用PEAR画图的方法简单讲一下(,免得自己以后忘了)。4
1. (至少)需要用到PEAR中的三个Image库:Image_Graph,Image_Canvas,Image_Color。下载它们并放到适当位置。
2. (一般来讲)要把PEAR所在位置加到php.ini所定义的incude_path中。
3. 需要一些TrueType的字体。“PEAR/Image/Canvas/Fonts/fontmap.txt”这个文件定义了相关的字体(文件)名字。(从网上或服务器上)找到这些字体文件,把这些字体文件放到系统某个位置。
4. 在“PEAR/Image/Canvas.php”文件中,定义常量“IMAGE_CANVAS_SYSTEM_FONT_PATH”。此常量用来指定字体文件所在位置。
 5. 参考“PEAR/Graph/docs”和“Graph/tests”下的多个画图的例子,挺简单的。这里就给两个和本文提到的离散图相关的例子(见右图):
5. 参考“PEAR/Graph/docs”和“Graph/tests”下的多个画图的例子,挺简单的。这里就给两个和本文提到的离散图相关的例子(见右图):5.1 “PEAR/Graph/docs/examples/double_category_axis.php”。
5.2 “PEAR/Graph/docs/examples/plot_scatter.php”。
在Serendipity中,可以使用方法二开发相关的图形统计插件。Deminy觉得自己写这个太浪费时间了,就免了。相信以后肯定会有人写的。
[注1] 上面提到的文章的作者使用的是一个叫做Swiff Chart软件制作统计图。
[注2] 如果你直接用Excel打开该XML文件困难的话,可能是因为缺乏必要的XML Schema信息。这时候,综合使用Excel的mapping功能,便可以将XML中的指定数据(pubDate)导入。
[注3] 以后有时间的话我会做具体数据的具体分析。
[注4] 此处相关代码和实现方式测试于3月24日下午。
类别:
内容管理软件XOOPS 2粗评
前两天答应给大温莎华人协会维护网站5后,初步考虑使用一款内容管理系统(CMS,content management system)来管理、维护整个网站。
在几种著名的基于PHP的CMS中,php-nuke名头最响、最老牌了,但现在收费了,而且基础架构好像没有postnuke好;但postnuke这个后期之秀开发了几年了,好像还是没什么明显的突破;另一个CMS产品phpWebSite是美国Appalachian州立大学开发的,一直就像大学里的实验产品,虽然开发了N年,但总是让人用起来感觉不爽(我一直觉得这个产品让人期望之余很失望);tiki给人的感觉不是最恰当的选择,更像一个信息、数据管理中心;Exponent Content Management System是这几者中最年轻的,也曾在sf.net上火过一把,但此后好像也没什么再出彩的地方了。
这样子算下来,XOOPS似乎应该是比较好的选择了。XOOPS的模块很多,功能完善,能和大名鼎鼎的Blog系统WordPress结合起来,而且还有中文的技术支持网站,所以乍看起来,不选XOOPS都不行了。
于是中午就下载了一份XOOPS v2.2.3安装、测试了一下。测试的结果只能用生气、呕血来形容。我本来不愿意浪费时间来写这个评测的,但是为了让我以后能够清晰地记住这个软件如何让人生气、失望,我还是详细地写写我的感受。
首先,安装v2.2.3后我发现该版本的官方语言包比较少,大概10来个,没有中文。于是,我用了个v2.0的中文简体语言包。此后,别的小瑕疵不说,单说选择语言为中文简体后,就会出现很多个程序运行警告信息。切换回英文错误信息少了很多,但还是有好几个,而且是核心程序里面出现的错误信息。也就是说,这个官方最新(稳定)版还是有明显的bug的。
因此,这时候我考虑用CVS下载最新的更新程序,然后对应地覆盖出错文件。可惜这般改动后错误信息依旧出现。无奈之余我就打开出错的这4、5个文件,发现了几个近乎白痴级别的程序设计错误:
1. /kernel/block.php里,getByModule()、getAllByGroupModule()、getAdminBlocks()、assignBlocks()被重复定义了2次,估计是开发人员复制、粘贴时候出的错。但是这种错误一测试就可以发现了呀,难道XOOPS的开发人员程序修改了之后都不测试就更新到CVS服务器里面去了??呕血。
2. /modules/newbb/language/english/modinfo.php里,用define重复定义"_MI_TEXT",这也是一测试就能测试出来的错误。
3. /kernel/module.php里,重复定义变量$_msg两次,而且这2次紧挨着,又是一个一测试就能测试出来的错误。
4. /class/theme.php里,在函数loadGlobalVars()里,用“if ($xoopsUser != '') {”,这里$xoopsUser是一个对象(object)。正确写法应该是“if (!empty($xoopsUser)) {”1。
5. 在某文件中,在定义某call by reference的函数的时候,返回布尔值,“return false”。正确写法应该返回某变量2。
待把这几个错误修正了之后,英文版的XOOP终于可以正常运行了。但是一但切换到中文,由于语言包兼容性等问题,仍然出现一大堆错误。XOOPS虽然的确支持多语言,但这方面做得并不很好,对语言处理过于生硬3。这直接导致的后果就是:我根本无法通过官方网站提供的资料使用中文版的XOOPS。
好在有国人搞了XOOPS中文版。但我对中国程序员改造后的程序向来感冒,看了中文版XOOPS网站的下载介绍后,我根本无意从那里下载中文版的XOOPS,因为我觉得如果使用了这个中文版,我就被这个“狭隘”的中文版套牢了,以后想要解套也许还要看那些中文版程序员的脸色行事,不妥。
其实当XOOPS设计成支持多语言后,那么所有的针对XOOPS某一特定语言的语言包的开发都应该归到XOOPS这一个旗号下,而不要脱裤子放屁——多此一举地另立一旗号出来(就像osCommerce日文版一样)。但问题是XOOPS的开发、管理、测试看起来在某些方面做得比较烂4,导致有些语言包根本无法在XOOPS下正常使用(这点也可以用来解释为什么XOOPS v2.2.3的官方语言包只有可怜的10来个)。在这种情况下,某些语言的开发者(例如中国的开发者)另立旗号也是可以理解的。
其实,XOOPS的确是个很好的产品。但一个团队中,良莠不齐也是很正常的事情,偏偏有几个菜鸟级的开发人员坏了XOOPS这锅鲜汤。无奈之余,XOOPS的fans们也只能静待下一版本(也许是v2.3)的XOOPS尽快出台了。
暂别XOOPS。
[注1] 这个错误在低版本的PHP中也许能够通过。我用的是PHP5。
[注2] 这个错误在低版本的PHP中也许能够通过。我用的是PHP5。
[注3] 举两个例子。首先,在XOOPS 2中,若某一语言文件缺失,则马上报错,但语言文件缺失在这种系统中是非常常见的一个现象。其次,在设置为中文简体后,页面标题是非正常显示的编码。
[注4] XOOPS中文版开发者曾就此抱怨过。
[补充说明5] 这里实际上不是为大温莎华人协会维护网站,而是要为温莎的中国艺术学院(义务)做一个新网站,特此澄清。2006-02-23 19:55:45
在几种著名的基于PHP的CMS中,php-nuke名头最响、最老牌了,但现在收费了,而且基础架构好像没有postnuke好;但postnuke这个后期之秀开发了几年了,好像还是没什么明显的突破;另一个CMS产品phpWebSite是美国Appalachian州立大学开发的,一直就像大学里的实验产品,虽然开发了N年,但总是让人用起来感觉不爽(我一直觉得这个产品让人期望之余很失望);tiki给人的感觉不是最恰当的选择,更像一个信息、数据管理中心;Exponent Content Management System是这几者中最年轻的,也曾在sf.net上火过一把,但此后好像也没什么再出彩的地方了。
这样子算下来,XOOPS似乎应该是比较好的选择了。XOOPS的模块很多,功能完善,能和大名鼎鼎的Blog系统WordPress结合起来,而且还有中文的技术支持网站,所以乍看起来,不选XOOPS都不行了。
于是中午就下载了一份XOOPS v2.2.3安装、测试了一下。测试的结果只能用生气、呕血来形容。我本来不愿意浪费时间来写这个评测的,但是为了让我以后能够清晰地记住这个软件如何让人生气、失望,我还是详细地写写我的感受。
首先,安装v2.2.3后我发现该版本的官方语言包比较少,大概10来个,没有中文。于是,我用了个v2.0的中文简体语言包。此后,别的小瑕疵不说,单说选择语言为中文简体后,就会出现很多个程序运行警告信息。切换回英文错误信息少了很多,但还是有好几个,而且是核心程序里面出现的错误信息。也就是说,这个官方最新(稳定)版还是有明显的bug的。
因此,这时候我考虑用CVS下载最新的更新程序,然后对应地覆盖出错文件。可惜这般改动后错误信息依旧出现。无奈之余我就打开出错的这4、5个文件,发现了几个近乎白痴级别的程序设计错误:
1. /kernel/block.php里,getByModule()、getAllByGroupModule()、getAdminBlocks()、assignBlocks()被重复定义了2次,估计是开发人员复制、粘贴时候出的错。但是这种错误一测试就可以发现了呀,难道XOOPS的开发人员程序修改了之后都不测试就更新到CVS服务器里面去了??呕血。
2. /modules/newbb/language/english/modinfo.php里,用define重复定义"_MI_TEXT",这也是一测试就能测试出来的错误。
3. /kernel/module.php里,重复定义变量$_msg两次,而且这2次紧挨着,又是一个一测试就能测试出来的错误。
4. /class/theme.php里,在函数loadGlobalVars()里,用“if ($xoopsUser != '') {”,这里$xoopsUser是一个对象(object)。正确写法应该是“if (!empty($xoopsUser)) {”1。
5. 在某文件中,在定义某call by reference的函数的时候,返回布尔值,“return false”。正确写法应该返回某变量2。
待把这几个错误修正了之后,英文版的XOOP终于可以正常运行了。但是一但切换到中文,由于语言包兼容性等问题,仍然出现一大堆错误。XOOPS虽然的确支持多语言,但这方面做得并不很好,对语言处理过于生硬3。这直接导致的后果就是:我根本无法通过官方网站提供的资料使用中文版的XOOPS。
好在有国人搞了XOOPS中文版。但我对中国程序员改造后的程序向来感冒,看了中文版XOOPS网站的下载介绍后,我根本无意从那里下载中文版的XOOPS,因为我觉得如果使用了这个中文版,我就被这个“狭隘”的中文版套牢了,以后想要解套也许还要看那些中文版程序员的脸色行事,不妥。
其实当XOOPS设计成支持多语言后,那么所有的针对XOOPS某一特定语言的语言包的开发都应该归到XOOPS这一个旗号下,而不要脱裤子放屁——多此一举地另立一旗号出来(就像osCommerce日文版一样)。但问题是XOOPS的开发、管理、测试看起来在某些方面做得比较烂4,导致有些语言包根本无法在XOOPS下正常使用(这点也可以用来解释为什么XOOPS v2.2.3的官方语言包只有可怜的10来个)。在这种情况下,某些语言的开发者(例如中国的开发者)另立旗号也是可以理解的。
其实,XOOPS的确是个很好的产品。但一个团队中,良莠不齐也是很正常的事情,偏偏有几个菜鸟级的开发人员坏了XOOPS这锅鲜汤。无奈之余,XOOPS的fans们也只能静待下一版本(也许是v2.3)的XOOPS尽快出台了。
暂别XOOPS。
[注1] 这个错误在低版本的PHP中也许能够通过。我用的是PHP5。
[注2] 这个错误在低版本的PHP中也许能够通过。我用的是PHP5。
[注3] 举两个例子。首先,在XOOPS 2中,若某一语言文件缺失,则马上报错,但语言文件缺失在这种系统中是非常常见的一个现象。其次,在设置为中文简体后,页面标题是非正常显示的编码。
[注4] XOOPS中文版开发者曾就此抱怨过。
[补充说明5] 这里实际上不是为大温莎华人协会维护网站,而是要为温莎的中国艺术学院(义务)做一个新网站,特此澄清。2006-02-23 19:55:45
类别:
粗评PHP写的留言本系统
上个星期在sf.net点击了人气最好的十几个PHP留言本系统,大致看了一下后挑出2个比较好的系统以备进一步的评测。这两个留言本系统,一个是Gbook MX,另外一个是YaBook。
晚上打算评测一下这两个系统,于是稍微详细地看了看它们的介绍。从功能上来讲,Gbook MX明显功能要强大得多,于是我就先评测它了。但是安装完毕后我发现,就这么一个列举了丰富功能的留言本系统,居然没有做客户端数据校验。也就是说,用户在提交留言的时候万一出现email写错了或者其他问题的情况下,他的留言就会丢失,他必须重写他的留言!这是不可容忍的一种现象。就这一点缺陷,就足够让我舍弃Gbook MX了。
YaBook目前是基于PHP5开发的,暂未评测。
随后我又找了一个叫做Advanced Guestbook的小有名气的留言本程序测试了一下。这个留言本同样缺乏客户端数据校验,并且在模版化、易用性方面有待提高,代码质量也有待增强,因此不值得采用。
总之,今天未发现令人满意的PHP留言本系统。难道因为留言本系统的结构简单,专业人士们懒得写这样的系统,于是反而就没有好的留言本系统?
[补充说明] 前一阵为了完成334课程的项目,曾在网上搜索了一通JSP/Servlet写的中文留言本系统,结果没有发现一个提得上台面的中文留言本系统,相反,垃圾类型的留言本系统倒是看到了一堆又一堆。吐血。
[补充说明2] 我最近几个月一直打算测试“Signkorn Guestbook”。遗憾的是无法找到这款商业版本的留言本最新版(v1.4)的完整演示版本,于是只好放弃。2006-11-02 21:31:01
晚上打算评测一下这两个系统,于是稍微详细地看了看它们的介绍。从功能上来讲,Gbook MX明显功能要强大得多,于是我就先评测它了。但是安装完毕后我发现,就这么一个列举了丰富功能的留言本系统,居然没有做客户端数据校验。也就是说,用户在提交留言的时候万一出现email写错了或者其他问题的情况下,他的留言就会丢失,他必须重写他的留言!这是不可容忍的一种现象。就这一点缺陷,就足够让我舍弃Gbook MX了。
YaBook目前是基于PHP5开发的,暂未评测。
随后我又找了一个叫做Advanced Guestbook的小有名气的留言本程序测试了一下。这个留言本同样缺乏客户端数据校验,并且在模版化、易用性方面有待提高,代码质量也有待增强,因此不值得采用。
总之,今天未发现令人满意的PHP留言本系统。难道因为留言本系统的结构简单,专业人士们懒得写这样的系统,于是反而就没有好的留言本系统?
[补充说明] 前一阵为了完成334课程的项目,曾在网上搜索了一通JSP/Servlet写的中文留言本系统,结果没有发现一个提得上台面的中文留言本系统,相反,垃圾类型的留言本系统倒是看到了一堆又一堆。吐血。
[补充说明2] 我最近几个月一直打算测试“Signkorn Guestbook”。遗憾的是无法找到这款商业版本的留言本最新版(v1.4)的完整演示版本,于是只好放弃。2006-11-02 21:31:01
类别:
新一代的PHP (3) - 展望PHP6
本文有待完成(但不一定会完成,并且素材有待准备)。
主要观点:PHP已经相当完善了,对PHP6可以不必期望太多。
主要观点:PHP已经相当完善了,对PHP6可以不必期望太多。
类别:
新一代的PHP (2) - 从PHP4迁移到PHP5
本文有待完成(但不一定会完成)。
主要观点:
1. 距离PHP5首次正式发布已经有16个月了,但目前PHP5的应用仍然有限,大量系统仍然基于PHP4。
2. PHP5已经足够成熟、可靠了(尤其是在昨天PHP v5.1.0发布后)。若不考虑兼容问题的话,新的应用系统可以完全抛弃PHP4了。
主要观点:
1. 距离PHP5首次正式发布已经有16个月了,但目前PHP5的应用仍然有限,大量系统仍然基于PHP4。
2. PHP5已经足够成熟、可靠了(尤其是在昨天PHP v5.1.0发布后)。若不考虑兼容问题的话,新的应用系统可以完全抛弃PHP4了。
类别:
新一代的PHP (1) - PHP5的新功能评价
[前言] 本文是对PHP5新功能的介绍和评价,其中引用了Adam Trachtenberg对PHP的一些新特性的介绍,但Deminy并未详细阅读Adam Trachtenberg原文。
本文是deminy自己对于PHP5新功能的个人理解,而不是对Adam Trachtenberg原文的翻译。本文不会深入讨论细节。
相对于PHP4而言,PHP5有几点重要的变化和改进。按照Adam Trachtenberg的理解,PHP5有三点最重要的改进:更全面的面向对象编程功能、MySQL扩展支持库MySQLi、改进的XML支持;另外,PHP5还有以下4点重要改进:内嵌的文本型数据库SQLite、错误处理、SOAP支持、简化的枚举操作。
一、更全面的面向对象编程功能
这点的重要性是无需多讨论的。PHP3已经开始部分支持面向对象编程了,但不够成熟,在对类的操作上有不够简洁之处(例如在类创建和类销毁的时候,缺乏相应的好的机制),因此面向对象编程并不能算是PHP3的主要特性。
看上去,PHP5的面向对象功能似乎就是Java语言的翻版,实现了传统的Java里面几乎所有的面向对象编程的相关概念,以至于有人在说:是不是PHP5要被Sun公司收购了?还有人又回过头去炒一些老话题:面向对象的PHP能否击溃同样面向对象的JSP?
更优的面向对象编程能力将对PHP的发展起到非常强劲的推动作用。这体现在两点。
现有的大量的PHP系统如果从PHP4升级到PHP5后,在内在结构的设计上可以有相当的改善,并且可以更好地借用现有的一些很好的面向对象的设计模式。PHP的内涵进一步升华了,这是第一点。
当Java凌空出世的时候,有人做了些C2Java之类的软件,把C程序转换成Java程序,但是这些C2Java的软件基本上都不能很完善地工作。但可以想象的是,Java2PHP(把Java转换成PHP)这样的系统开发起来要容易的多。由于PHP的面向对象能力和Java极其相似,很多Java开发的系统可以轻松地移植、转换成PHP。我个人觉得,一些原来基于Java/JSP的系统将会转移到PHP来,而且这可能成为一个潮流。这是第二点。
二、MySQL扩展支持库MySQLi
这点也没有多少需要讨论的。当MySQL支持预处理等功能后,PHP自然也应该实现对应的功能。实际上,在数据库支持这块,MySQL要做的工作远比PHP要做的多得多。
三、改进的XML支持
这点很重要。此前给我的印象是,PHP对XML的支持始终不够强劲,对XML的处理能力比较差、不灵活,以至于好些人都避免用PHP的XML功能。如果翻阅网上大家发布的一些用PHP4写的XML相关类库,就会发现,很多人对XML操作的时候,都是使用其它方式实现的,而不是PHP里面的XML相关函数。我没有测试过PHP5对XML的支持,但相信PHP5会在这方面做得很好。
四、内嵌的文本型数据库SQLite
这个太棒了,是中小型PHP应用的福音(要知道,相当多的PHP系统都是中小型的)。我想很多PHP程序员都写过基于文本存储的应用程序(例如用文本方式保存的留言本),那种编程感觉是让人有些不爽的,尤其是在数据格式发生变更或者数据导入、导出的时候。
内嵌SQLite真是一个好想法!中小型系统由此不需要依赖MySQL或者其它数据库软件,也不必去使用脆弱的纯文本去存储数据,但是我们依然可以建造一个健壮的系统!我们开发的基于SQLite的系统未来可以轻松移植到其它数据库软件上,我们甚至可以用ADOdb去操作SQLite!
(注:如果deminy依然坚持不在deminy.net上使用MySQL之类的数据库软件的话,但至少,deminy肯定会使用SQLite来改写自己的blog、留言本等程序。2)
五、错误处理
我并没有详细阅读这方面的文档,但可以想象得到这个改进很棒。早期的PHP纵容错误的发生,并且放任错误的发生,虽然使得编程容易了点,但也导致了一些开发方面的问题。如果PHP能够在错误处理方面大大加强的话,无疑在两个方面会得到很重要的改进:一是开发过程中的错误跟踪和调试;二是系统实现(业务)过程中对于流程方面的错误处理将会更容易被合理的处理。
(对于这一点,deminy没有具体研究PHP5的新的错误处理机制,只是通过对Java和PHP相关的错误处理机制的对比而做了一些探讨,说得很泛泛。或有谬误。)
六、内置对SOAP的支持
这个很棒。我估计在PHP5之前,PHP里SOAP的实现,是需要通过第三方类库来实现的(也许PEAR里面也支持SOAP,但我不知道)。比较有名的第三方类库是NuSOAP,但我个人对NuSOAP在web上承受高压的性能不很放心(去看看NuSOAP的代码就知道了,长长的!)。
现在PHP5内置了对SOAP的支持。也许在PHP里用SOAP的人不是很多,但是对于那些在PHP中使用SOAP的人,PHP5无疑是很好的一个福音,至少,SOAP编程在PHP5里面变得明显的简单了(关于这一点可以在phpclasses.org下载SOAP相关的代码做研究)。
七、简化的枚举操作
这也是个很棒的实用型的东西,完全符合PHP的设计思想:简化编程。翻来覆去地看,PHP大体上就那么几块主要的东西:数据库操作、文件流读写、循环/枚举等。对枚举操作的高度简化是一个很棒的想法,这是PHP程序员很喜欢的一个新特性!
总结:哪些新特性更重要?
我个人觉得:更全面的面向对象编程功能是最重要的;错误处理的引入有必要,但错误处理机制执行效果如何,还有待评估;更好的MySQL扩展支持库MySQLi、改进的XML支持这两点对于较大型的PHP应用更有帮助;其它三点(内嵌的文本型数据库SQLite、内置对SOAP的支持和简化的枚举操作)则属于小敲小打类型的,但非常实用,尤其是内嵌SQLite!
因此,我对这些新特性的重要性评估如下:
1. 更全面的面向对象编程功能
2. 错误处理机制 (有待进一步评估)
3. MySQL扩展支持库MySQLi
3. 改进的XML支持
4. 内嵌的文本型数据库SQLite
5. 内置对SOAP的支持
5. 简化的枚举操作
[注1] 有妄言之处,欢迎指正。
[注2] 在PHP5的时代,用传统文本方式来编写留言本之类的系统,也许是应该遭到嘲笑的。因为我们有了SQLite!(虽然SQLite不是万能的)
[补充说明] 也许有人奇怪,PHP5正式推出了16个月后,deminy才来评价它,为什么?有三个原因。首先,相对于PHP4而言,PHP5拥有一些重大变化,因此在PHP5推出来后,大家很多时候还对它持观望态度,并没有具体应用它,也没有深入去研究它,deminy也是一样;其次,就现在而言,PHP5已经让大多数人开始感到它已经是成熟的技术了,deminy也开始考虑移植到PHP5了,因此开始对PHP5作了一些具体了解,并产生了一些快感(感到PHP5吻合了deminy的一些需求),并想把这些快感用文字的形式发泄出来;最后一点是,昨天PHP推出了具有重要改进的一个版本v5.1.0,这是导致deminy决定写这篇文字的直接动力:PHP程序员现在应该有足够的信心移植到一个新的、稳定的平台上去了!
本文是deminy自己对于PHP5新功能的个人理解,而不是对Adam Trachtenberg原文的翻译。本文不会深入讨论细节。
相对于PHP4而言,PHP5有几点重要的变化和改进。按照Adam Trachtenberg的理解,PHP5有三点最重要的改进:更全面的面向对象编程功能、MySQL扩展支持库MySQLi、改进的XML支持;另外,PHP5还有以下4点重要改进:内嵌的文本型数据库SQLite、错误处理、SOAP支持、简化的枚举操作。
一、更全面的面向对象编程功能
这点的重要性是无需多讨论的。PHP3已经开始部分支持面向对象编程了,但不够成熟,在对类的操作上有不够简洁之处(例如在类创建和类销毁的时候,缺乏相应的好的机制),因此面向对象编程并不能算是PHP3的主要特性。
看上去,PHP5的面向对象功能似乎就是Java语言的翻版,实现了传统的Java里面几乎所有的面向对象编程的相关概念,以至于有人在说:是不是PHP5要被Sun公司收购了?还有人又回过头去炒一些老话题:面向对象的PHP能否击溃同样面向对象的JSP?
更优的面向对象编程能力将对PHP的发展起到非常强劲的推动作用。这体现在两点。
现有的大量的PHP系统如果从PHP4升级到PHP5后,在内在结构的设计上可以有相当的改善,并且可以更好地借用现有的一些很好的面向对象的设计模式。PHP的内涵进一步升华了,这是第一点。
当Java凌空出世的时候,有人做了些C2Java之类的软件,把C程序转换成Java程序,但是这些C2Java的软件基本上都不能很完善地工作。但可以想象的是,Java2PHP(把Java转换成PHP)这样的系统开发起来要容易的多。由于PHP的面向对象能力和Java极其相似,很多Java开发的系统可以轻松地移植、转换成PHP。我个人觉得,一些原来基于Java/JSP的系统将会转移到PHP来,而且这可能成为一个潮流。这是第二点。
二、MySQL扩展支持库MySQLi
这点也没有多少需要讨论的。当MySQL支持预处理等功能后,PHP自然也应该实现对应的功能。实际上,在数据库支持这块,MySQL要做的工作远比PHP要做的多得多。
三、改进的XML支持
这点很重要。此前给我的印象是,PHP对XML的支持始终不够强劲,对XML的处理能力比较差、不灵活,以至于好些人都避免用PHP的XML功能。如果翻阅网上大家发布的一些用PHP4写的XML相关类库,就会发现,很多人对XML操作的时候,都是使用其它方式实现的,而不是PHP里面的XML相关函数。我没有测试过PHP5对XML的支持,但相信PHP5会在这方面做得很好。
四、内嵌的文本型数据库SQLite
这个太棒了,是中小型PHP应用的福音(要知道,相当多的PHP系统都是中小型的)。我想很多PHP程序员都写过基于文本存储的应用程序(例如用文本方式保存的留言本),那种编程感觉是让人有些不爽的,尤其是在数据格式发生变更或者数据导入、导出的时候。
内嵌SQLite真是一个好想法!中小型系统由此不需要依赖MySQL或者其它数据库软件,也不必去使用脆弱的纯文本去存储数据,但是我们依然可以建造一个健壮的系统!我们开发的基于SQLite的系统未来可以轻松移植到其它数据库软件上,我们甚至可以用ADOdb去操作SQLite!
(注:如果deminy依然坚持不在deminy.net上使用MySQL之类的数据库软件的话,但至少,deminy肯定会使用SQLite来改写自己的blog、留言本等程序。2)
五、错误处理
我并没有详细阅读这方面的文档,但可以想象得到这个改进很棒。早期的PHP纵容错误的发生,并且放任错误的发生,虽然使得编程容易了点,但也导致了一些开发方面的问题。如果PHP能够在错误处理方面大大加强的话,无疑在两个方面会得到很重要的改进:一是开发过程中的错误跟踪和调试;二是系统实现(业务)过程中对于流程方面的错误处理将会更容易被合理的处理。
(对于这一点,deminy没有具体研究PHP5的新的错误处理机制,只是通过对Java和PHP相关的错误处理机制的对比而做了一些探讨,说得很泛泛。或有谬误。)
六、内置对SOAP的支持
这个很棒。我估计在PHP5之前,PHP里SOAP的实现,是需要通过第三方类库来实现的(也许PEAR里面也支持SOAP,但我不知道)。比较有名的第三方类库是NuSOAP,但我个人对NuSOAP在web上承受高压的性能不很放心(去看看NuSOAP的代码就知道了,长长的!)。
现在PHP5内置了对SOAP的支持。也许在PHP里用SOAP的人不是很多,但是对于那些在PHP中使用SOAP的人,PHP5无疑是很好的一个福音,至少,SOAP编程在PHP5里面变得明显的简单了(关于这一点可以在phpclasses.org下载SOAP相关的代码做研究)。
七、简化的枚举操作
这也是个很棒的实用型的东西,完全符合PHP的设计思想:简化编程。翻来覆去地看,PHP大体上就那么几块主要的东西:数据库操作、文件流读写、循环/枚举等。对枚举操作的高度简化是一个很棒的想法,这是PHP程序员很喜欢的一个新特性!
总结:哪些新特性更重要?
我个人觉得:更全面的面向对象编程功能是最重要的;错误处理的引入有必要,但错误处理机制执行效果如何,还有待评估;更好的MySQL扩展支持库MySQLi、改进的XML支持这两点对于较大型的PHP应用更有帮助;其它三点(内嵌的文本型数据库SQLite、内置对SOAP的支持和简化的枚举操作)则属于小敲小打类型的,但非常实用,尤其是内嵌SQLite!
因此,我对这些新特性的重要性评估如下:
1. 更全面的面向对象编程功能
2. 错误处理机制 (有待进一步评估)
3. MySQL扩展支持库MySQLi
3. 改进的XML支持
4. 内嵌的文本型数据库SQLite
5. 内置对SOAP的支持
5. 简化的枚举操作
[注1] 有妄言之处,欢迎指正。
[注2] 在PHP5的时代,用传统文本方式来编写留言本之类的系统,也许是应该遭到嘲笑的。因为我们有了SQLite!(虽然SQLite不是万能的)
[补充说明] 也许有人奇怪,PHP5正式推出了16个月后,deminy才来评价它,为什么?有三个原因。首先,相对于PHP4而言,PHP5拥有一些重大变化,因此在PHP5推出来后,大家很多时候还对它持观望态度,并没有具体应用它,也没有深入去研究它,deminy也是一样;其次,就现在而言,PHP5已经让大多数人开始感到它已经是成熟的技术了,deminy也开始考虑移植到PHP5了,因此开始对PHP5作了一些具体了解,并产生了一些快感(感到PHP5吻合了deminy的一些需求),并想把这些快感用文字的形式发泄出来;最后一点是,昨天PHP推出了具有重要改进的一个版本v5.1.0,这是导致deminy决定写这篇文字的直接动力:PHP程序员现在应该有足够的信心移植到一个新的、稳定的平台上去了!
类别:
"Ruby on Rails"技术观后感 (2)
看完"Ruby on Rails"后,Deminy产生了一个问题:怎样把"Ruby on Rails"的概念移植到PHP中,构建(所谓的)"PHP on Rails"呢?1
这个思路是可能行得通的。
首先,"Ruby on Rails"是基于Rails架构、用Ruby这样一个面向对象(Object Oriented)的编程语言实现的。PHP是一个面向过程(Procedure Oriented)的编程语言,但也是一个面向对象的编程语言。既然"Ruby on Rails"可行,"PHP on Rails"也应该是可行的。
其次,一项技术的竞争力和难点往往在于它的设计,而不在于它所依赖的编程语言。就像新产品最难的地方往往是设计,而不是投产(所以新产品设计出来后,马上就可能出现很多仿造的产品)。类似地,当"Ruby on Rails"被设计出来了,人们很容易把这项技术类似地推广到"Java on Rails"、"PHP on Rails"等。
基于上面两点分析,通过Internet搜索,可以发现如下五项主要的"PHP on Rails"技术可以考虑:Biscuit、PHP on TRAX、TaniPHP、Cake、Symfony 。暂无时间测试它们,无法评价。但目前似乎Biscuit相对要更成熟点。
[注1] 也许有人会问,既然已经有了"Ruby on Rails",干嘛还要研究"PHP on Rails"呢?原因有好些,其中一个合理的原因是:不愿意为了实施一项技术而要求所有相关技术人员多学一门无太大意义的语言。
[注2] 接前文“'Ruby on Rails'技术观后感 (1)”。
这个思路是可能行得通的。
首先,"Ruby on Rails"是基于Rails架构、用Ruby这样一个面向对象(Object Oriented)的编程语言实现的。PHP是一个面向过程(Procedure Oriented)的编程语言,但也是一个面向对象的编程语言。既然"Ruby on Rails"可行,"PHP on Rails"也应该是可行的。
其次,一项技术的竞争力和难点往往在于它的设计,而不在于它所依赖的编程语言。就像新产品最难的地方往往是设计,而不是投产(所以新产品设计出来后,马上就可能出现很多仿造的产品)。类似地,当"Ruby on Rails"被设计出来了,人们很容易把这项技术类似地推广到"Java on Rails"、"PHP on Rails"等。
基于上面两点分析,通过Internet搜索,可以发现如下五项主要的"PHP on Rails"技术可以考虑:Biscuit、PHP on TRAX、TaniPHP、Cake、Symfony 。暂无时间测试它们,无法评价。但目前似乎Biscuit相对要更成熟点。
[注1] 也许有人会问,既然已经有了"Ruby on Rails",干嘛还要研究"PHP on Rails"呢?原因有好些,其中一个合理的原因是:不愿意为了实施一项技术而要求所有相关技术人员多学一门无太大意义的语言。
[注2] 接前文“'Ruby on Rails'技术观后感 (1)”。
类别:
Lilina v0.7修补说明
[引子] Lilina的最新版本v0.7中文化仍然存在一定的问题。Deminy综合先前对其所做的测试和修改,总结如下6点供参考。
1. 该软件使用utf-8作为页面编码。如果要在页面标题中使用中文标题,应对conf.php文件内相关设定做如下类似修改:
// 将gb2312编码的文字转换成utf-8编码
$SITETITLE = mb_convert_encoding("Deminy收藏的RSS内容", "utf-8", "gb2312") ;
2. 由于页面程序执行过程可能很长(并因此导致超时),因此最好在conf.php文件中增加一行
set_time_limit(0); // 允许程序一直执行下去
3. 文件index.php对MAGPIE_CACHE_AGE的重新定义无效,因为此前在conf.php已经定义过了。(此条可能有待商榷)
正确的一种修改方式应该是在conf.php中修改相应部分为2:
if (empty($_GET[force_update]) && empty($_SERVER['argv'][1]))
define('MAGPIE_CACHE_AGE',60 * 60 * 3);
else
define('MAGPIE_CACHE_AGE', 1);
4. 该软件使用一个第三方PHP类Snoopy,版本号v1.0。Snoopy.class.inc文件的curl相应变量($curl_path)需要根据服务器配置重新设定。注意总共有2个Snoopy.class.inc文件:一个在./extlib/下,另外一个在./inc/extlib/.下。
6. 在./conf.php中增加一行
define('MAGPIE_FETCH_TIME_OUT', 360);
7. 经过上一步的修改后,并不能保证./index.php?force_update=1(强制更新RSS内容)能够有效地通过浏览器访问 (但可以通过命令行运行该程序,例如命令“php index.php force_update=1”)。
不能通过浏览器有效访问的原因是程序执行时间过长,导致超时。有几个地方可能中断程序执行:客户端浏览器的最长链接时间限制、服务器端服务器允许的程序运行最长时限、Snoopy程序中的fsockopen连接(用于读取RSS内容)超时。另外,如果以上都未超时,某些HTTP协议的具体实现方式也可能规定在指定时限内没有数据传输则断开HTTP连接。
如果仍然出现访问超时的情形,建议用户尝试使用以下做法避免超时(但暂不能明确确定具体是哪一种原因导致超时2):
7.1 Snoopy.class.inc中将$_fp_timeout设一个比较大的值,例如180(基本没有什么效果);
7.2 去处那些访问困难的RSS种子,或者将其移到最后(无可奈何之举);
7.3 使用cron脚本通过命令行执行“php index.php force_update=1”,而不要通过浏览器(最好的办法)。
[注1] $_SERVER['argv'][1]参数是为了便于用命令行方式强制更新,主要用于cron。此处写法非常简略。
[注2] 如果在页面执行的时候能够不断输出HTML,则不会出现超时的现象。
1. 该软件使用utf-8作为页面编码。如果要在页面标题中使用中文标题,应对conf.php文件内相关设定做如下类似修改:
// 将gb2312编码的文字转换成utf-8编码
$SITETITLE = mb_convert_encoding("Deminy收藏的RSS内容", "utf-8", "gb2312") ;
2. 由于页面程序执行过程可能很长(并因此导致超时),因此最好在conf.php文件中增加一行
set_time_limit(0); // 允许程序一直执行下去
3. 文件index.php对MAGPIE_CACHE_AGE的重新定义无效,因为此前在conf.php已经定义过了。(此条可能有待商榷)
正确的一种修改方式应该是在conf.php中修改相应部分为2:
if (empty($_GET[force_update]) && empty($_SERVER['argv'][1]))
define('MAGPIE_CACHE_AGE',60 * 60 * 3);
else
define('MAGPIE_CACHE_AGE', 1);
4. 该软件使用一个第三方PHP类Snoopy,版本号v1.0。Snoopy.class.inc文件的curl相应变量($curl_path)需要根据服务器配置重新设定。注意总共有2个Snoopy.class.inc文件:一个在./extlib/下,另外一个在./inc/extlib/.下。
6. 在./conf.php中增加一行
define('MAGPIE_FETCH_TIME_OUT', 360);
7. 经过上一步的修改后,并不能保证./index.php?force_update=1(强制更新RSS内容)能够有效地通过浏览器访问 (但可以通过命令行运行该程序,例如命令“php index.php force_update=1”)。
不能通过浏览器有效访问的原因是程序执行时间过长,导致超时。有几个地方可能中断程序执行:客户端浏览器的最长链接时间限制、服务器端服务器允许的程序运行最长时限、Snoopy程序中的fsockopen连接(用于读取RSS内容)超时。另外,如果以上都未超时,某些HTTP协议的具体实现方式也可能规定在指定时限内没有数据传输则断开HTTP连接。
如果仍然出现访问超时的情形,建议用户尝试使用以下做法避免超时(但暂不能明确确定具体是哪一种原因导致超时2):
7.1 Snoopy.class.inc中将$_fp_timeout设一个比较大的值,例如180(基本没有什么效果);
7.2 去处那些访问困难的RSS种子,或者将其移到最后(无可奈何之举);
7.3 使用cron脚本通过命令行执行“php index.php force_update=1”,而不要通过浏览器(最好的办法)。
[注1] $_SERVER['argv'][1]参数是为了便于用命令行方式强制更新,主要用于cron。此处写法非常简略。
[注2] 如果在页面执行的时候能够不断输出HTML,则不会出现超时的现象。
类别:
对《Smarty的分页实现》一文的最后回复
[引子] 前两天在网上看到一篇谈(针对小项目的)web分页实现的文字(见此),其做法是丛数据库中取出所有记录集(而不管实际需要哪页的记录集),然后用空循环的方式定位到指定的记录集所在位置并提取。由此引发一通讨论。本文是deminy对该文的最后回复。
本文涉及到的关键字: PHP Smarty ADOdb 数据库分页
1. 你在评论中说,你“不是经不起批评”,而是我的口气让人不爽。抱歉,实在是因为你的设计中的缺陷太明显、太典型了,是一种设计思想上的严重缺陷,而这种思想是每个技术人员都应该避免和制止的,让人不得不说。难道你的作品就批评不得?难不成我批评的时候还要刻意的先恭维恭维你?被人批评后感觉爽不爽要看对方的言辞,但也要看自己对批评的理解和觉悟。我顺手指出你的问题所在,你就从点到面地开始反驳起来。既然彼此都不易不饶,那我也只好奉陪了。 :D
2. 我相信你曾花了(点)时间研究过别人的(数据库)分页技术,但是如果你细看一下的话,你会发现,别人的分页技术都没有采用你的思路,为什么?很简单,因为你的思路是(完全)不可取的。不要以为那些分页技术的设计者们比你差,恰恰相反,他们对具体技术的应用往往比你久,他们的实战经验往往比你丰富得多(得多),而且,他们的智商往往也不低于你。
3.你文中说“不过分页类库不一定适合Smarty,特别是当记录集数据是二维数组时”。希望你再去好好研究一下Smarty的文档、然后再写点程序测试一下再这么说吧。事实上,Smarty支持多维数组都是没有问题的。其实,Smarty比别的绝大多数模板厉害的其中一点就在于别的模板引擎绝大多数无法支持多维数组变量(甚至连一维数组都不支持),而Smarty可以。对于基于PHP+DB的项目来讲,在模板引擎中对多维数组变量的支持是非常重要的,因为数据库的结果集是以数组的形式返回的。4
4. 你在评论中说,“但是希望有深入的讨论,而不是这样的泛泛而谈。 ”。在我前面的几篇讨论中,我已经清晰、具体地告诉你,你的设计的“致命伤在于浪费资源,而且是没有意义地在浪费资源。”;我还提到,单就MySQL而言,它的分页类也是比较难设计的,并指出主要的原因;后来,我还告诉你,我具体地查了一下ADOdb的分页技术(实际上我是翻阅了其中几处关键代码),认为ADOdb的分页技术可以直接应用,因此可以不必要自己再费劲去设计分页;最后,我还清晰、具体地告诉你,几种数据库(例如MySQL/Oracle/MS SQL)的分页技术是不一样的,因此好的(通用的)分页类是很难写的;在本文的讨论中,你还会看到我对Smarty和ADOdb的一些具体技术方面的讨论。我想,你不会再以为我还是在和你“泛泛而谈”了吧?
5. 你在评论中说,“分页类要是还依赖于数据库,那都耦合成什么样了,怎么扩展。”。很抱歉,这点我懒得评论,浪费口舌。我只能认为你的数据库开发经验还是肤浅的。分页这项需求是紧密地和数据库相关的,如果没有数据库,那么也就不需要这么费劲地讨论分页问题了;分页类的设计是一项非常具体的web技术应用,而不是一种泛泛的理论、一种泛泛的思路,可以被随便挂在嘴上当做谈资。如果你对一项技术的具体应用不是很熟悉,就不要试图发表一些不够成熟的、却又貌似权威的看法。(顺便问一句,如你所说若分页类需要扩展的话,分页类的扩展方向是什么?)
6. 你在评论中说,你的设计思路是“数据库->分页类。分页类是完全独立的,类中不包括其它任何对象。”。的确,你说“分页类是完全独立的”是正确的,但那是因为你的分页类根本就没做记录集分页的核心部分。基本上来讲你的分页类主要是实现了输出不同页码(坦率的说,这属于分页技术里面的边角料的活,初级程序员都可以用几个循环来实现)和显示结果记录集,但是最关键的记录集查询时候的分页你却没做,而却把它交给了Smarty,而且让Smarty去用一种低级的手法去实现。
7. 至于你文中所说的“看到一个号称分页类终结者的,哈哈,有点好笑。分页类中把SQL都包含进去了,这个是绝对不能容忍的,可以说作者对OO的认识还比较浅。”,显然也是荒谬的,该被好笑的是你。分页(原则上)是用SQL实现的,当然要用到SQL,而且这跟OO(面向对象)没什么关系。如果你只会这么生搬硬套OO的概念,建议你还是再实战两年后再讨论吧。
8. 你在评论中说,“而deminy(的思路)是 分页类(包含数据库连接)。 ”。这点你倒说对了,没有数据库连接,是没法(有效)分页的。注意,我说的是有效(率)的分页。这点是一目了然的。如果这点你都不能理解,你最好先好好地开发几个基于数据库的产品/项目后再来讨论吧(不要把业余的留言本等也当成项目)。
9. 你在评论中说,如果用ADOdb的话,万一“换了个数据库系统,你又要重写分页部分的代码。 ”,“但是ADODB并不是大家开发的标准,不是所有人都用数据库抽象层。很多项目就是针对某种数据库的,如果需要作数据库移植,你就连分页类都要修改”,这两句话毫无正确性可言,而且我已经明确告诉你了,“ADOdb对于分页的处理机制比较好”。如果把你的这两句话贴给那些用过ADOdb的技术人员去看看的话,他们会笑话你一知半解的。我想你对ADOdb没有深入了解过,对ADOdb的数据集处理机制你更没有研究过。
10. 你在评论中说,“分页就是两个思路:一种整个结果集读入内存,只需要一次查询,占用内存多,但效率高;另一种读取部分记录,多次对数据库查询,占用内存少,效率视情况而定,如果用户多,数据库并发查询数目过多也可能导致一些问题。 ”。我建议你讨论的时候不要一时冲动而说一些很不严谨的话。单就我们当前讨论的简单话题(从数据库查询记录后分页输出)而言,把你这段话随便拿给绝大多数的数据库相关开发人员(不管是用VB/C++/Delphi/Java的,还是DBA)看,都会告诉你不妥的。前一种思路在web上一无可取之处,连Java web server这种使用了服务器端cache技术的服务器都不会这样做。
11. 你在评论中说,你认为“面对不同规模的项目就是要采用不同的方法。”。是地,这句话没错,但是一些基本原则还是要遵循的。退一步而言,你用这样的垃圾思路在小项目中也的确无妨的,但如果把它当成一个经验贴出来,那可是贻笑大方的。
12. 别的方面(例如软件架构、软件设计模式)等话题就太广了,争议更多,说出来都是扯皮了。
13. 再退一步来讲的话,你可以说你的讨论仅限于Smarty,而不涉及数据库问题。即使这样的话,你也可以检查检查你的那段循环取值程序(这是你的设计中的两个主要部分之一),看看是不是很垃圾:
{section name="list" loop=$productID start=0 max=$pager_Total step=1}
{if ($smarty.section.list.index >= $pager_StartNum )&& ($smarty.section.list.index <= $pager_EndNum )}
......
简洁来写就是:
for (i = 0; i < size_of_array; i++)
if ((i >= a) && (i <= b))
// do sth here.这段是伪代码,不是PHP代码
看出来你的程序的问题了没有?你试图从数组中取一个区间(例如区间(a,b)),于是你用了一个空循环从数组开始的地方一直空循环到a,然后取出a到b的元素,然后继续空循环到数组末尾!3不要跟我说while/for/section这类的循环结构是应该这样用来对数组操作的。(如果你还不懂在Smarty中如何更有效率地写这段代码的话,那就去好好读读Smarty中相关文档吧)
大体上来讲,从你文中使用的技术(Smarty)来看是你是个中级程序员的水平,但从你文中对数据库知识的理解、从你的程序设计能力以及由此反映出来的程序设计思想水平来看,是个初级程序员的水准。
14. 另外,从头到尾你都在偏执地、教条地理解我的意思,教条地套用软件开发中的“教科书”言论来解释事理,却缺乏具体的、有说服力的实战例子(例如具体的有价值的项目应用)。在这篇讨论中,你也许知道某些技术名词,但不知道些技术名词的具体含义,但你却试图在你不熟悉、不大了解的技术方面充当行家和权威。在这篇讨论中,你对概念僵硬地套用的能力超越了你对概念具体应用的能力。也许在网上,对概念的夸夸其谈更能够吸引眼球,但更能推动技术进步的做法是对概念的实际应用。(顺便说一句,我也很看不起拉大旗做虎皮的人。)
15. 看看吧,你的一篇原创文字(包括回复),在技术上有如此众多可以被他人指正的地方,并且连入门级的(技术方案设计)思路都没有端正,然后你还好意思说你是在义务地给我“普及知识”?你以为你有这个资格?太可笑兼无知了。
16. 不要认为你能够翻译、转载一些有价值的技术文字就代表你的水平好,就代表你就是权威。翻译技术文字不代表你理解了其中的意思,就像很多翻译计算机书籍的人,自己都不大懂书里面说的是什么。顺便说一句,我还是很赞赏你翻译文章的行为的(因为的确很有必要),但是要记得尊重版权、尊重原作者,而且,也要尊重原文的原始意思。
完。
[注1] 原讨论见此。本地镜像 (取自2005-11-14 16:42:39左右)。
[注2] 居然为讨论这么低级、浅显的技术问题而花了这么多篇幅,惭愧。谢绝在本站继续讨论这个问题。
[注3] 这段代码的问题在于其执行一些不必要的空循环操作,在无意义地浪费资源。这个问题是可以通过简单地改写一下代码就可以解决的,如下所示:
for (i = a; i <= b; i++)
// do sth here.这段是伪代码,不是PHP代码
对小项目来讲,这点资源的浪费的确不是很重要,但是其中反映出来的程序设计思想是欠佳的。另外,关于效率问题,请参阅我的一篇文字《为什么程序效率仍然很重要》。2005-11-14 21:24:51
[注4] 此段讨论误解了原作者(haohappy)意思,删除。2005-11-15 01:03:11
[注5] 对你最新回复的回复
前五点不评价,或者不再讨论。但下面会讨论一下你在第六点后面的一些话题。
你说,“我做过的数据库应用应该不比你少,你叫我去实战?你拿出一个我完全没有做过的数据库应用吧? 或者你自己得意的一套数据库相关代码出来让我分析一下?”Hoho,如果攀比彼此做过的数据库应用多少,我想是没有多大意思的。但是如果你真要比的话,那我告诉你,我在tom.com工作期间(14个月),相当一段时间是带领一个团队负责tom整个网站大部分在线互动程序(PHP为主)的开发的。考虑一下整个门户网站对在线互动程序的需求,你自己算算我可能经手过多少个项目吧(你没有这种经历,是无法想象的)。
你也许会说,“你经手那么多项目,不一定都是你做的呀”。是的,但是每个项目如何实现我都要先大体考虑清楚后才能给其他同事去做(实际上我自己也要自己动手做很多项目);如果我不能在某些方面服众,我就无法领导好一个团队。我觉得,我在tom工作期间的表现是基本称职的。
你也许还会说,“你做过很多项目不一定代表你牛啊、不一定代表你水平高啊”。是的,从编程能力来讲,我从来没有把自己当成一个高级程序员的水平,我对自己现在的编程能力的定位也就是一个很称职的中等偏上的程序员水平。我有时候会对朋友说,我说我不喜欢自己写程序,因为我写出来的程序不属于最漂亮的行列;但是,我的眼光比我的编程能力高,我能够看到好些一般程序员看不到的问题,这就是为什么我大概只有中级程序员的编程水平、但却具备中级偏上的素质。
另外,成为高级程序员不是我的追求。我眼高手低,我更喜欢的是借用别人的代码实现自己的思路,我更欣赏的是别人的代码和思想,例如Smarty的设计,就是我非常推崇的一套设计方案(虽然我没有大规模用过它)。
这种比较是无聊的。自信心不需要靠这样的攀比来建立的。每个人都有优点和缺点的。
最后,过两天我会隐藏(不是删除)这篇文字的,一则我不喜欢自己帖子里面有不妥的过激言论,二则我不喜欢技术争论,三是影响我修行的效果,尤其在我修行尚未到家的时候 :$。2005-11-15 01:09:56
本文涉及到的关键字: PHP Smarty ADOdb 数据库分页
1. 你在评论中说,你“不是经不起批评”,而是我的口气让人不爽。抱歉,实在是因为你的设计中的缺陷太明显、太典型了,是一种设计思想上的严重缺陷,而这种思想是每个技术人员都应该避免和制止的,让人不得不说。难道你的作品就批评不得?难不成我批评的时候还要刻意的先恭维恭维你?被人批评后感觉爽不爽要看对方的言辞,但也要看自己对批评的理解和觉悟。我顺手指出你的问题所在,你就从点到面地开始反驳起来。既然彼此都不易不饶,那我也只好奉陪了。 :D
2. 我相信你曾花了(点)时间研究过别人的(数据库)分页技术,但是如果你细看一下的话,你会发现,别人的分页技术都没有采用你的思路,为什么?很简单,因为你的思路是(完全)不可取的。不要以为那些分页技术的设计者们比你差,恰恰相反,他们对具体技术的应用往往比你久,他们的实战经验往往比你丰富得多(得多),而且,他们的智商往往也不低于你。
3.
4. 你在评论中说,“但是希望有深入的讨论,而不是这样的泛泛而谈。 ”。在我前面的几篇讨论中,我已经清晰、具体地告诉你,你的设计的“致命伤在于浪费资源,而且是没有意义地在浪费资源。”;我还提到,单就MySQL而言,它的分页类也是比较难设计的,并指出主要的原因;后来,我还告诉你,我具体地查了一下ADOdb的分页技术(实际上我是翻阅了其中几处关键代码),认为ADOdb的分页技术可以直接应用,因此可以不必要自己再费劲去设计分页;最后,我还清晰、具体地告诉你,几种数据库(例如MySQL/Oracle/MS SQL)的分页技术是不一样的,因此好的(通用的)分页类是很难写的;在本文的讨论中,你还会看到我对Smarty和ADOdb的一些具体技术方面的讨论。我想,你不会再以为我还是在和你“泛泛而谈”了吧?
5. 你在评论中说,“分页类要是还依赖于数据库,那都耦合成什么样了,怎么扩展。”。很抱歉,这点我懒得评论,浪费口舌。我只能认为你的数据库开发经验还是肤浅的。分页这项需求是紧密地和数据库相关的,如果没有数据库,那么也就不需要这么费劲地讨论分页问题了;分页类的设计是一项非常具体的web技术应用,而不是一种泛泛的理论、一种泛泛的思路,可以被随便挂在嘴上当做谈资。如果你对一项技术的具体应用不是很熟悉,就不要试图发表一些不够成熟的、却又貌似权威的看法。(顺便问一句,如你所说若分页类需要扩展的话,分页类的扩展方向是什么?)
6. 你在评论中说,你的设计思路是“数据库->分页类。分页类是完全独立的,类中不包括其它任何对象。”。的确,你说“分页类是完全独立的”是正确的,但那是因为你的分页类根本就没做记录集分页的核心部分。基本上来讲你的分页类主要是实现了输出不同页码(坦率的说,这属于分页技术里面的边角料的活,初级程序员都可以用几个循环来实现)和显示结果记录集,但是最关键的记录集查询时候的分页你却没做,而却把它交给了Smarty,而且让Smarty去用一种低级的手法去实现。
7. 至于你文中所说的“看到一个号称分页类终结者的,哈哈,有点好笑。分页类中把SQL都包含进去了,这个是绝对不能容忍的,可以说作者对OO的认识还比较浅。”,显然也是荒谬的,该被好笑的是你。分页(原则上)是用SQL实现的,当然要用到SQL,而且这跟OO(面向对象)没什么关系。如果你只会这么生搬硬套OO的概念,建议你还是再实战两年后再讨论吧。
8. 你在评论中说,“而deminy(的思路)是 分页类(包含数据库连接)。 ”。这点你倒说对了,没有数据库连接,是没法(有效)分页的。注意,我说的是有效(率)的分页。这点是一目了然的。如果这点你都不能理解,你最好先好好地开发几个基于数据库的产品/项目后再来讨论吧(不要把业余的留言本等也当成项目)。
9. 你在评论中说,如果用ADOdb的话,万一“换了个数据库系统,你又要重写分页部分的代码。 ”,“但是ADODB并不是大家开发的标准,不是所有人都用数据库抽象层。很多项目就是针对某种数据库的,如果需要作数据库移植,你就连分页类都要修改”,这两句话毫无正确性可言,而且我已经明确告诉你了,“ADOdb对于分页的处理机制比较好”。如果把你的这两句话贴给那些用过ADOdb的技术人员去看看的话,他们会笑话你一知半解的。我想你对ADOdb没有深入了解过,对ADOdb的数据集处理机制你更没有研究过。
10. 你在评论中说,“分页就是两个思路:一种整个结果集读入内存,只需要一次查询,占用内存多,但效率高;另一种读取部分记录,多次对数据库查询,占用内存少,效率视情况而定,如果用户多,数据库并发查询数目过多也可能导致一些问题。 ”。我建议你讨论的时候不要一时冲动而说一些很不严谨的话。单就我们当前讨论的简单话题(从数据库查询记录后分页输出)而言,把你这段话随便拿给绝大多数的数据库相关开发人员(不管是用VB/C++/Delphi/Java的,还是DBA)看,都会告诉你不妥的。前一种思路在web上一无可取之处,连Java web server这种使用了服务器端cache技术的服务器都不会这样做。
11. 你在评论中说,你认为“面对不同规模的项目就是要采用不同的方法。”。是地,这句话没错,但是一些基本原则还是要遵循的。退一步而言,你用这样的垃圾思路在小项目中也的确无妨的,但如果把它当成一个经验贴出来,那可是贻笑大方的。
12. 别的方面(例如软件架构、软件设计模式)等话题就太广了,争议更多,说出来都是扯皮了。
13. 再退一步来讲的话,你可以说你的讨论仅限于Smarty,而不涉及数据库问题。即使这样的话,你也可以检查检查你的那段循环取值程序(这是你的设计中的两个主要部分之一),看看是不是很垃圾:
{section name="list" loop=$productID start=0 max=$pager_Total step=1}
{if ($smarty.section.list.index >= $pager_StartNum )&& ($smarty.section.list.index <= $pager_EndNum )}
......
简洁来写就是:
for (i = 0; i < size_of_array; i++)
if ((i >= a) && (i <= b))
// do sth here.这段是伪代码,不是PHP代码
看出来你的程序的问题了没有?你试图从数组中取一个区间(例如区间(a,b)),于是你用了一个空循环从数组开始的地方一直空循环到a,然后取出a到b的元素,然后继续空循环到数组末尾!3不要跟我说while/for/section这类的循环结构是应该这样用来对数组操作的。(如果你还不懂在Smarty中如何更有效率地写这段代码的话,那就去好好读读Smarty中相关文档吧)
大体上来讲,从你文中使用的技术(Smarty)来看是你是个中级程序员的水平,但从你文中对数据库知识的理解、从你的程序设计能力以及由此反映出来的程序设计思想水平来看,是个初级程序员的水准。
14. 另外,从头到尾你都在偏执地、教条地理解我的意思,教条地套用软件开发中的“教科书”言论来解释事理,却缺乏具体的、有说服力的实战例子(例如具体的有价值的项目应用)。在这篇讨论中,你也许知道某些技术名词,但不知道些技术名词的具体含义,但你却试图在你不熟悉、不大了解的技术方面充当行家和权威。在这篇讨论中,你对概念僵硬地套用的能力超越了你对概念具体应用的能力。也许在网上,对概念的夸夸其谈更能够吸引眼球,但更能推动技术进步的做法是对概念的实际应用。(顺便说一句,我也很看不起拉大旗做虎皮的人。)
15. 看看吧,你的一篇原创文字(包括回复),在技术上有如此众多可以被他人指正的地方,并且连入门级的(技术方案设计)思路都没有端正,然后你还好意思说你是在义务地给我“普及知识”?你以为你有这个资格?太可笑兼无知了。
16. 不要认为你能够翻译、转载一些有价值的技术文字就代表你的水平好,就代表你就是权威。翻译技术文字不代表你理解了其中的意思,就像很多翻译计算机书籍的人,自己都不大懂书里面说的是什么。顺便说一句,我还是很赞赏你翻译文章的行为的(因为的确很有必要),但是要记得尊重版权、尊重原作者,而且,也要尊重原文的原始意思。
完。
[注1] 原讨论见此。本地镜像 (取自2005-11-14 16:42:39左右)。
[注2] 居然为讨论这么低级、浅显的技术问题而花了这么多篇幅,惭愧。谢绝在本站继续讨论这个问题。
[注3] 这段代码的问题在于其执行一些不必要的空循环操作,在无意义地浪费资源。这个问题是可以通过简单地改写一下代码就可以解决的,如下所示:
for (i = a; i <= b; i++)
// do sth here.这段是伪代码,不是PHP代码
对小项目来讲,这点资源的浪费的确不是很重要,但是其中反映出来的程序设计思想是欠佳的。另外,关于效率问题,请参阅我的一篇文字《为什么程序效率仍然很重要》。2005-11-14 21:24:51
[注4] 此段讨论误解了原作者(haohappy)意思,删除。2005-11-15 01:03:11
[注5] 对你最新回复的回复
前五点不评价,或者不再讨论。但下面会讨论一下你在第六点后面的一些话题。
你说,“我做过的数据库应用应该不比你少,你叫我去实战?你拿出一个我完全没有做过的数据库应用吧? 或者你自己得意的一套数据库相关代码出来让我分析一下?”Hoho,如果攀比彼此做过的数据库应用多少,我想是没有多大意思的。但是如果你真要比的话,那我告诉你,我在tom.com工作期间(14个月),相当一段时间是带领一个团队负责tom整个网站大部分在线互动程序(PHP为主)的开发的。考虑一下整个门户网站对在线互动程序的需求,你自己算算我可能经手过多少个项目吧(你没有这种经历,是无法想象的)。
你也许会说,“你经手那么多项目,不一定都是你做的呀”。是的,但是每个项目如何实现我都要先大体考虑清楚后才能给其他同事去做(实际上我自己也要自己动手做很多项目);如果我不能在某些方面服众,我就无法领导好一个团队。我觉得,我在tom工作期间的表现是基本称职的。
你也许还会说,“你做过很多项目不一定代表你牛啊、不一定代表你水平高啊”。是的,从编程能力来讲,我从来没有把自己当成一个高级程序员的水平,我对自己现在的编程能力的定位也就是一个很称职的中等偏上的程序员水平。我有时候会对朋友说,我说我不喜欢自己写程序,因为我写出来的程序不属于最漂亮的行列;但是,我的眼光比我的编程能力高,我能够看到好些一般程序员看不到的问题,这就是为什么我大概只有中级程序员的编程水平、但却具备中级偏上的素质。
另外,成为高级程序员不是我的追求。我眼高手低,我更喜欢的是借用别人的代码实现自己的思路,我更欣赏的是别人的代码和思想,例如Smarty的设计,就是我非常推崇的一套设计方案(虽然我没有大规模用过它)。
这种比较是无聊的。自信心不需要靠这样的攀比来建立的。每个人都有优点和缺点的。
最后,过两天我会隐藏(不是删除)这篇文字的,一则我不喜欢自己帖子里面有不妥的过激言论,二则我不喜欢技术争论,三是影响我修行的效果,尤其在我修行尚未到家的时候 :$。2005-11-15 01:09:56
类别:
如何修复eGroupWare邮件乱码问题
程序: eGroupWare
版本: v1.0.0.009
问题: 邮件显示标题和内容均为乱码。此现象应该会出现在所有使用东亚文字的该系统中。
文件: email/inc/class.mail_msg_base.inc.php
函数: htmlspecialchars_encode($str, $charset='')
行数: 5188-5191左右
改写为:
1 if (!$charset)
2 {
3 $charset = "gb2312"; // 修改,仅对中文简体有效
4 }
5 $str = mb_convert_encoding($str, "UTF-8", $charset); // 新增
6 $str = htmlentities($str, ENT_QUOTES, $charset);
[补充说明1] 该bug同样出现在eGroupWare v1.0.0.007中。Deminy所提供的是一个治标的方法,并未全面研究email部分代码,只解决了邮件阅读时的乱码的问题,但未解决发送的邮件中的乱码问题。
[补充说明2] 该系统多处调用函数htmlspecialchars_encode时,并未使用第二个参数,导致该系统的邮件部分并未能实现真正的支持多语言。
版本: v1.0.0.009
问题: 邮件显示标题和内容均为乱码。此现象应该会出现在所有使用东亚文字的该系统中。
文件: email/inc/class.mail_msg_base.inc.php
函数: htmlspecialchars_encode($str, $charset='')
行数: 5188-5191左右
改写为:
1 if (!$charset)
2 {
3 $charset = "gb2312"; // 修改,仅对中文简体有效
4 }
5 $str = mb_convert_encoding($str, "UTF-8", $charset); // 新增
6 $str = htmlentities($str, ENT_QUOTES, $charset);
[补充说明1] 该bug同样出现在eGroupWare v1.0.0.007中。Deminy所提供的是一个治标的方法,并未全面研究email部分代码,只解决了邮件阅读时的乱码的问题,但未解决发送的邮件中的乱码问题。
[补充说明2] 该系统多处调用函数htmlspecialchars_encode时,并未使用第二个参数,导致该系统的邮件部分并未能实现真正的支持多语言。
