技术细节
Drupal系列谈(1) - 谈使用Drupal 7
通常,人们喜欢把Drupal视为一套内容管理框架,而我更愿意把它看成是一个建站系统,一个一流的、完善的建站系统。它强大的建站功能,首先,得益于自身设计的高度开放性、可扩展性;其次,得益于在这种高度开放性、可扩展性上而衍生出来的大量的功能组件(modules)、模版(themes)以及语言包(translations)。截止目前,仅就Drupal官方网站正式立项的项目而言,有10989个功能组件、1201个模版以及97个语言包。
2011年1月5日,当Drupal最新一代的版本, Drupal 7.0正式发布的时候,我曾快速做了一个计划,计划在2011年7月4日,也就是7.0正式发布半年后将我的Drupal 6网站全数升级到Drupal 7。之所以要等半年,是因为大部分Drupal功能组件要么还不支持Drupal 7,要么还缺乏平滑升级到Drupal 7的升级方式。当时,我预期半年后,我所使用的几十个Drupal 6功能组件应该大部分都已完成了对Drupal 7的支持并且提供自动升级方式。
半年后的今天,我并没有如期地完整这个升级步骤,原因有两个。一是我在Drupal 6上使用的50来个组件中还有9个左右的组件不支持Drupal 7;二是相当一部分的组件的升级可能需要一定程度的手工操作或存在风险,例如CCK。同样由于这两个原因,在未来的几个月内,我都不会考虑把现有网站从Drupal 6升级到Drupal 7。
由于知道从Drupal 6升级到Drupal 7存在诸多困难,因此,自年初以来,当需要新建一个网站的时候,我都是在Drupal 7建站,虽然在Drupal 7上建站存在一个很明显的问题:很多成熟的、重要的组件要么不支持Drupal 7,要么就是还处在开发阶段,存在各种bug。
半年来,在Drupal 7上,我累计安装、使用了52个开源组件(不包括自己编写的),大体上和在Drupal 6上使用的组件数量相当。这其中,80%以上的都是使用的dev版本。所谓dev版本,就是还在开发中的版本,连Alpha版本可能都不是,更别谈Beta、RC版本了。
目前相当部分处于dev版本状态下的Drupal 7组件其实已经比较稳定了。某些dev版本下的组件可能还存在些明显的bug,不过这种情况下一般都会有使用者汇报并且有人提供补丁,因此,如果自己会打补丁的话,还是可以用的。我目前所使用的50多个Drupal 7组件中,仅有一个组件的dev版本存在问题且长期没有修复,需要我自己根据他人提供的反馈打补丁。
说了上面这么多,最主要的是为了总结并分享我目前对Drupal 7的如下三点使用经验:
(1). Drupal 7已可以取代Drupal 6使用在正式网站上。也许你会跟我说:“这是废话,Drupal 7如果不能使用在正式网站上,还能叫正式版本吗?”我只能跟你说:没有了各种功能组件的支持,Drupal也许就是鸡肋,什么都不是。
(2). 大部分主要的组件,例如多网站支持、多域名支持、搜索引擎优化以及电子商务方面的组件,都已支持Drupal 7,虽然不少依然处于dev版本状态。
(3). 目前,如果使用Drupal 7的组件,应该比较大胆地使用dev版本,而不要死等到稳定版出来的日期,因为那可能是遥遥无期的。关于这一点,我举个典型的例子。FAQ (常见问题)是Drupal中非常好的一个组件,但是它的Drupal 7版本目前还是2011-02-25年发布的dev版本。用户对这个版本已经反馈了超过10个bug,但它的开发人员却一直没有更新。我在苦等了几个月后,终于自己动手,根据用户提供的各种补丁,在dev版本上打了9个补丁,然后使用它。(目前为止,这是唯一一个需要我自己来打补丁修复bug的Drupal 7组件。)
2011年1月5日,当Drupal最新一代的版本, Drupal 7.0正式发布的时候,我曾快速做了一个计划,计划在2011年7月4日,也就是7.0正式发布半年后将我的Drupal 6网站全数升级到Drupal 7。之所以要等半年,是因为大部分Drupal功能组件要么还不支持Drupal 7,要么还缺乏平滑升级到Drupal 7的升级方式。当时,我预期半年后,我所使用的几十个Drupal 6功能组件应该大部分都已完成了对Drupal 7的支持并且提供自动升级方式。
半年后的今天,我并没有如期地完整这个升级步骤,原因有两个。一是我在Drupal 6上使用的50来个组件中还有9个左右的组件不支持Drupal 7;二是相当一部分的组件的升级可能需要一定程度的手工操作或存在风险,例如CCK。同样由于这两个原因,在未来的几个月内,我都不会考虑把现有网站从Drupal 6升级到Drupal 7。
由于知道从Drupal 6升级到Drupal 7存在诸多困难,因此,自年初以来,当需要新建一个网站的时候,我都是在Drupal 7建站,虽然在Drupal 7上建站存在一个很明显的问题:很多成熟的、重要的组件要么不支持Drupal 7,要么就是还处在开发阶段,存在各种bug。
半年来,在Drupal 7上,我累计安装、使用了52个开源组件(不包括自己编写的),大体上和在Drupal 6上使用的组件数量相当。这其中,80%以上的都是使用的dev版本。所谓dev版本,就是还在开发中的版本,连Alpha版本可能都不是,更别谈Beta、RC版本了。
目前相当部分处于dev版本状态下的Drupal 7组件其实已经比较稳定了。某些dev版本下的组件可能还存在些明显的bug,不过这种情况下一般都会有使用者汇报并且有人提供补丁,因此,如果自己会打补丁的话,还是可以用的。我目前所使用的50多个Drupal 7组件中,仅有一个组件的dev版本存在问题且长期没有修复,需要我自己根据他人提供的反馈打补丁。
说了上面这么多,最主要的是为了总结并分享我目前对Drupal 7的如下三点使用经验:
(1). Drupal 7已可以取代Drupal 6使用在正式网站上。也许你会跟我说:“这是废话,Drupal 7如果不能使用在正式网站上,还能叫正式版本吗?”我只能跟你说:没有了各种功能组件的支持,Drupal也许就是鸡肋,什么都不是。
(2). 大部分主要的组件,例如多网站支持、多域名支持、搜索引擎优化以及电子商务方面的组件,都已支持Drupal 7,虽然不少依然处于dev版本状态。
(3). 目前,如果使用Drupal 7的组件,应该比较大胆地使用dev版本,而不要死等到稳定版出来的日期,因为那可能是遥遥无期的。关于这一点,我举个典型的例子。FAQ (常见问题)是Drupal中非常好的一个组件,但是它的Drupal 7版本目前还是2011-02-25年发布的dev版本。用户对这个版本已经反馈了超过10个bug,但它的开发人员却一直没有更新。我在苦等了几个月后,终于自己动手,根据用户提供的各种补丁,在dev版本上打了9个补丁,然后使用它。(目前为止,这是唯一一个需要我自己来打补丁修复bug的Drupal 7组件。)
类别:
一个关于SQL的技术问题
目前我还没有发现很好的在线剪贴板工具。通常如果碰到需要零时记录一些事情的时候,我往往会打开Google的notebook网站(该服务已经不对新用户开放了),在里面随手把需要记录的资料贴上去。然后每隔一些日子,清理掉一些过时的临时记录。
今晚清理Google notebook记录的时候,看到下面两段SQL查询语句,是我前几个月在工作时顺手整理的一个问题临时存在了那里,于是贴出来,算是一个技术方面的小问题在网上分享一下:这两个查询语句的区别是什么?
上面两个SQL语句是用MySQL写的。如果需要该问题的数据表结构(和模拟数据),可以在WikiPedia英文网站的“Join (SQL)”一文中找到。
答案我就不更新在网志里了,相信迟早访客回复里面会有正解的。
今晚清理Google notebook记录的时候,看到下面两段SQL查询语句,是我前几个月在工作时顺手整理的一个问题临时存在了那里,于是贴出来,算是一个技术方面的小问题在网上分享一下:这两个查询语句的区别是什么?
SELECT
*
FROM
Employee e
LEFT JOIN Department d
ON e.DepartmentID = d.DepartmentID
WHERE
d.DepartmentName IS NOT NULL
*
FROM
Employee e
LEFT JOIN Department d
ON e.DepartmentID = d.DepartmentID
WHERE
d.DepartmentName IS NOT NULL
SELECT
*
FROM
Employee e
LEFT JOIN Department d
ON e.DepartmentID = d.DepartmentID AND d.DepartmentName IS NOT NULL
*
FROM
Employee e
LEFT JOIN Department d
ON e.DepartmentID = d.DepartmentID AND d.DepartmentName IS NOT NULL
上面两个SQL语句是用MySQL写的。如果需要该问题的数据表结构(和模拟数据),可以在WikiPedia英文网站的“Join (SQL)”一文中找到。
答案我就不更新在网志里了,相信迟早访客回复里面会有正解的。
类别:
OWASP"2010十大安全隐患"
周五的午后,看到朋友的RSS种子上转了一篇别人的网志《安全漏洞的原因》 (by fs_knownsec,由于内容不算我特别愿意推荐的,因此也就不链接到原文了),想到了OWASP(开放式web应用程序安全项目)这个项目,进而想把它的最新进展在网志上共享一下。
顾名思义,OWASP(开放式web应用程序安全项目)关注web应用程序的安全。OWASP这个项目最有名的,也许就是它的“十大安全隐患列表”。这个列表不但总结了web应用程序最可能、最常见、最危险的十大安全隐患,还包括了如何消除这些隐患的建议。(另外,OWASP还有一些辅助项目和指南来帮助IT公司和开发团队来规范应用程序开发流程和测试流程,提高web产品的安全性。)这个“十大”差不多每隔三年更新一次,目前的最新版是《Top 10 2007》(2007年十大web安全隐患列表,该链接指向的是英文版的)。ZDNET上有一系列中文文章《OWASP 10要素增强Web应用程序安全》(一共七篇),对2007年的这个十大有详细的介绍,有兴趣的同学建议去阅读一下。
“OWASP Top 10 2010”大概将在2010年第一季度发布,目前处于发布前最后的征询意见(RC, request for comments)的阶段。本文将对“OWASP Top 10 2010”RC版本做一个简要的介绍。以下凡是提到“OWASP Top 10 2010”之处均指其RC版本。
和“Top 10 2007”相比,“top 10 2010”有如下主要改动:
- 明确指出,“十大”指的是十大安全隐患(top 10 risks),而非十大最常见的缺陷或薄弱环节(not top 10 most common weaknesses)。
- 修改了用于评估安全隐患的排名规则,而非仅仅依赖于安全隐患所关联的缺陷的流行程度和范围。这一点会影响新的“十大”的排名次序。
- 在最新版的“十大”中,用两个新的安全隐患替代两个旧的安全隐患:
- 添加新的第6大安全隐患:错误的安全配置 (Security Misconfiguration)。这曾经是“Top 10 2004”当中的第10大安全隐患,后来因为觉得这不属于软件问题而从“Top 10 2007”当中移除了。但是,从应用程序使用、配置方面的安全隐患程度和常见性来讲,足以重新将这条列入十大。
- 添加新的第8大安全隐患: 未经验证的网址重定向 (Unvalidated Redirects and Forwards)。有证据表明有关于此的安全问题已经相当普遍,并且可能造成明显的危害。
- 删除旧的第3大安全隐患: 不安全的远程文件引用和执行 (Malicious File Execution。注:此非意译)。这依然是一个普遍存在的严重的安全问题。不过,它在2007年前后的空前的普遍流行相当程度上是因为当时很多PHP 程序存在这个安全隐患。目前,PHP的默认设置中已经对此做了更多的安全方面的弥补和限制,使得这个安全隐患不再像过去那么普遍。
- 删除旧的第6大安全隐患: 信息泄露和不恰当的错误处理 (Information Leakage and Improper Error Handling)。这个问题相当流行,不过危害程度一般比较有限。
以下是最新的OWASP Top 10 2010 (RC版本,可以从这里下载到官方英文PDF文档,更多官方英文信息可以参考这里):
- A1 – 注入 (Injection)
- A2 – 跨站脚本 (Cross Site Scripting (XSS))
- A3 – 无效的验证和会话管理 (Broken Authentication and Session Management)
- A4 – 对资源不安全的直接引用 (Insecure Direct Object References)
- A5 – 跨站伪造请求 (Cross Site Request Forgery (CSRF))
- A6 – 错误的安全配置 (Security Misconfiguration) (新加入)
- A7 – 失败的网址访问权限限制 (Failure to Restrict URL Access)
- A8 – 未经验证的网址重定向 (Unvalidated Redirects and Forwards) (新加入)
- A9 – 不安全的密码存储 (Insecure Cryptographic Storage)
- A10 – 薄弱的传输层保护 (Insufficient Transport Layer Protection)
类别:
一道关于PHP的代码题
我们公司招聘PHP开发人员的时候,电话面试之前会有一个笔试。也就是说,给应聘者几道PHP语言和MySQL数据库开发方面相关的问题,再给他一个晚上的时间来回答这些问题;第二天早上之前应聘者需将答案通过电子邮件发回来,随后公司的核心开发人员会根据其回答问题的情况来决定是否需要进行下一阶段的面试(电话面试或当面面试)。
设计比较好一点的技术方面的问题是比较困难的,因此公司常常也会让新来的开发人员设计几道问题以供参考。
2007年12月4日(周二),我在编写程序生成两份数据报告的时候,根据程序调试过程中出现的问题总结了如下一道问题。这个问题着重考察对PHP中变量引用(variable reference,相当于C里面的指针)、数组遍历这两方面的掌握,需要对相关知识有清晰的理解才能回答准确。这类问题并不一定适合在面试的时候用,不过,用这个问题来温习一下PHP中的一些技术要点还是有些意思的,因此我一直把这个问题收录着。
<?php
$data = array('a', 'b', 'c');
foreach ($data as $key => $val) {
$val = &$data[$key];
}
?>
问题1: 程序执行时,每一次循环结束后变量$data的值是什么?请解释。
问题2: 程序执行完以后,变量$data的值是什么?请解释。
补充说明:本文草稿完成于2008-10-21。
设计比较好一点的技术方面的问题是比较困难的,因此公司常常也会让新来的开发人员设计几道问题以供参考。
2007年12月4日(周二),我在编写程序生成两份数据报告的时候,根据程序调试过程中出现的问题总结了如下一道问题。这个问题着重考察对PHP中变量引用(variable reference,相当于C里面的指针)、数组遍历这两方面的掌握,需要对相关知识有清晰的理解才能回答准确。这类问题并不一定适合在面试的时候用,不过,用这个问题来温习一下PHP中的一些技术要点还是有些意思的,因此我一直把这个问题收录着。
<?php
$data = array('a', 'b', 'c');
foreach ($data as $key => $val) {
$val = &$data[$key];
}
?>
问题1: 程序执行时,每一次循环结束后变量$data的值是什么?请解释。
问题2: 程序执行完以后,变量$data的值是什么?请解释。
补充说明:本文草稿完成于2008-10-21。
类别:
在网上搜索信息 (3) —— 搜索个人信息实战举例
声明:本文引用了一些第三方图片、文字、链接等,用以解释有关技术思考的过程。但这些资料已经涉及侵犯他人隐私,随时可能被删。
 今天(周五)下班回到家来,又累又没什么特别的事情要做。于是倒了杯红酒,打算把自己灌得半梦半醒之间好好睡一觉。
今天(周五)下班回到家来,又累又没什么特别的事情要做。于是倒了杯红酒,打算把自己灌得半梦半醒之间好好睡一觉。
把酒杯拿回房间,边喝酒边上网。打开jiaoyou8,首页随机出现了一个四川MM的图片(如右图)。一看还不错,于是点进去,看到MM在“征友信息”的最后留下的一句话:
“请友人们自己查询偶留给网站的联系方式”
jiaoyou8禁止公开留下个人联系方式,但有些网友是会通过一些技巧留下自己联系方式的蛛丝马迹的。难道这个MM如此冰雪聪明,竟然能够突破jiaoyou8的文字封锁留下自己联系方式的蛛丝马迹?于是我把这个MM在jiaoyou为数不多的自我介绍和文字研究了一遍,却没发现什么蛛丝马迹,只是从照片背景建筑上发现这个MM居然和我是校友(四川大学毕业)。
略一沉思,觉得这MM应该不会聪明到会透过猜谜方式留联系方式的地步。于是把自己的思维方式“降格”成菜鸟的上网智商水平,再从头到尾翻一遍其个人介绍,还是没发现所谓的“偶留给网站的联系方式”1。
这个MM在jiaoyou8留下的有效信息极少。但此时,我已决定通过搜索的方式把她从网上翻出来,并把我搜索的思考过程记录下来。幸运的是,我经过不多的几个搜索步骤就把这个MM的大体资料从网上搜索出来了。下面就是我的搜索过程。
至此,我已经颇有把握能够搜索出更多的信息,但我停止了进一步的搜索。我已经证明了自己搜索过程中的思路是正确的、有效的,已经满足了,没有必要把人家翻个底朝天。
本次信息搜索在美西时间2007年4月13日晚6时左右进行。
睡觉去了。
[注1] 随后我认为,其所说的“偶留给网站的联系方式”也就是注册的时候留给网站的联系方式,未付费用户无法查阅这些联系方式。
 今天(周五)下班回到家来,又累又没什么特别的事情要做。于是倒了杯红酒,打算把自己灌得半梦半醒之间好好睡一觉。
今天(周五)下班回到家来,又累又没什么特别的事情要做。于是倒了杯红酒,打算把自己灌得半梦半醒之间好好睡一觉。把酒杯拿回房间,边喝酒边上网。打开jiaoyou8,首页随机出现了一个四川MM的图片(如右图)。一看还不错,于是点进去,看到MM在“征友信息”的最后留下的一句话:
“请友人们自己查询偶留给网站的联系方式”
jiaoyou8禁止公开留下个人联系方式,但有些网友是会通过一些技巧留下自己联系方式的蛛丝马迹的。难道这个MM如此冰雪聪明,竟然能够突破jiaoyou8的文字封锁留下自己联系方式的蛛丝马迹?于是我把这个MM在jiaoyou为数不多的自我介绍和文字研究了一遍,却没发现什么蛛丝马迹,只是从照片背景建筑上发现这个MM居然和我是校友(四川大学毕业)。
略一沉思,觉得这MM应该不会聪明到会透过猜谜方式留联系方式的地步。于是把自己的思维方式“降格”成菜鸟的上网智商水平,再从头到尾翻一遍其个人介绍,还是没发现所谓的“偶留给网站的联系方式”1。
这个MM在jiaoyou8留下的有效信息极少。但此时,我已决定通过搜索的方式把她从网上翻出来,并把我搜索的思考过程记录下来。幸运的是,我经过不多的几个搜索步骤就把这个MM的大体资料从网上搜索出来了。下面就是我的搜索过程。
- 总结一下。目前从jiaoyou8上知道的关于这个MM比较有效的信息是:ID是“rolane”,女,约24岁(之所以用“约”是因为jiaoyou8的年龄信息误差较大),四川人(指四川出生或在四川工作),至少目前还在国内。另外,根据其留在jiaoyou8上的照片知道她应该是四川大学毕业的。
- Google是我的最爱,于是第一步就是用其ID“rolane”在Google上搜索。很不幸,搜出来一堆垃圾信息,就不用细看搜索结果了。
- 马上开始转换策略。既然这个MM还在国内,那就“百度”一下她吧。只是这次用百度搜索的时候我多加了个搜索关键字:用“rolane 四川大学”来搜索。
这次只有一条搜索结果,来自“未名空间”。是这个MM在未名空间第一次注册的时候系统自动生成的一个页面,其中包含如下内容:
我是 rolane (Joan ), 来自 60.164.
从“痕迹学”上来讲,未名空间的这个“Fri Mar 23 05:52:09 2007”左右新注册的用户rolane和jiaoyou8的rolane是同一个人。 - 通过上一个步骤,我们知道了另外两条信息。一是这个MM除了喜欢用rolane这个ID以外,很可能还喜欢用Joan做自己的英文名;另外一条信息是:这个MM目前使用“60.164.”这个IP网段。从她的上网水平等角度来考虑,这个IP网段应该是该MM的真实IP所在网段。
- 使用DomainTools搜索“60.164.”这个网段。结果如下:
inetnum: 60.164.0.0 - 60.165.255.255
netname: CHINANET-GS
descr: CHINANET Gansu province network
descr: China Telecom
据此猜测该MM目前的地理位置应该是“甘肃省”,使用“中国电信”的上网服务。 - 此时我停顿了一下,思考下一步该怎么进一步搜索。
- 随后我决定用“rolane 甘肃”作为关键字再次百度。从百度的搜索结果简介上看,前三条结果(1,2,3)似乎和我们要搜索的MM有紧密联系。
经过对比我们之前已经掌握的一些资料(大学学校、出国意向、大致年龄)和百度前三条搜索结果(都是占卜网站上的帖子)所透露出来的信息,我们发现二者信息高度吻合,因此也就可以确认占卜网站上的帖子也是同一个MM“rolane”发出来的。 - 这个MM在占卜网站发帖占卜自己婚姻的同时,也比较详细地写下了自己的个人信息、情感经历、未来计划等等。
当我阅读该MM的两个占卜咨询帖的时候,忍不住大笑起来:因为我已经成功地把一个人的信息搜出来了。
至此,我已经颇有把握能够搜索出更多的信息,但我停止了进一步的搜索。我已经证明了自己搜索过程中的思路是正确的、有效的,已经满足了,没有必要把人家翻个底朝天。
本次信息搜索在美西时间2007年4月13日晚6时左右进行。
睡觉去了。
[注1] 随后我认为,其所说的“偶留给网站的联系方式”也就是注册的时候留给网站的联系方式,未付费用户无法查阅这些联系方式。
类别:
去除wmv等文件的数字版权保护
前两天有一网友向我咨询如何去除wmv文件的DRM(Digital Rights Management,可以理解为“数字版权保护”)。
为此这两天我研究了一下,看了看网上相关文章,例如《用DRM2WMV解码珊瑚礁成功思路》等等。这类文章所述过程冗长、复杂,需要的技术能力较高,而且对Windows Media Player等软件的版本有较苛刻的要求,实施起来比较麻烦(可以说相当麻烦)。
后来我读到一篇文字,《How to remove DRM from WMV, ASF, WMA (Windows Media) files with valid licenses using Automate unDRM 2.0》,据此顺藤摸瓜,从该页找到了一个去除wmv文件数字版权保护的免费软件“FairUse4WM v1.3”。
刚才下载、运行、使用该软件后,经过不太复杂的几个步骤,就成功地去除了某wmv文件的数字版权保护。
需要注意的是,这种“去除数字版权保护”的操作和“破解数字版权保护”的操作是有区别的。就本文讨论的内容(去除数字版权保护)而言,首先要求你有相关wmv文件版权保护方面的密码,然后才能去除其版权保护。“破解数字版权保护”(也就是破解数字版权保护的密码)在目前看来是不太可能的。
我本来有意为此做一个视频解说,一步步指引如何去除wmv文件的数字版权保护,但觉得比较浪费时间,就免了。
善用技术。
为此这两天我研究了一下,看了看网上相关文章,例如《用DRM2WMV解码珊瑚礁成功思路》等等。这类文章所述过程冗长、复杂,需要的技术能力较高,而且对Windows Media Player等软件的版本有较苛刻的要求,实施起来比较麻烦(可以说相当麻烦)。
后来我读到一篇文字,《How to remove DRM from WMV, ASF, WMA (Windows Media) files with valid licenses using Automate unDRM 2.0》,据此顺藤摸瓜,从该页找到了一个去除wmv文件数字版权保护的免费软件“FairUse4WM v1.3”。
刚才下载、运行、使用该软件后,经过不太复杂的几个步骤,就成功地去除了某wmv文件的数字版权保护。
需要注意的是,这种“去除数字版权保护”的操作和“破解数字版权保护”的操作是有区别的。就本文讨论的内容(去除数字版权保护)而言,首先要求你有相关wmv文件版权保护方面的密码,然后才能去除其版权保护。“破解数字版权保护”(也就是破解数字版权保护的密码)在目前看来是不太可能的。
我本来有意为此做一个视频解说,一步步指引如何去除wmv文件的数字版权保护,但觉得比较浪费时间,就免了。
善用技术。
类别:
Serendipity插件使用 (1)——内容重写 (Content Rewriter)
参数设置
外挂名称 (Plugin-Title):
该插件在你网志的插件列表中的可识别名称。此处可为任意可识别标题,种族歧视内容除外。
改写字符 (Rewrite string):
将要重写的内容的模版。这里需要使用特殊标记“{from}”和“{to}”。前者({from})对应于下面“改写名称/新改写名称 (Title #/New Title)”文本区域中的内容,后者({to})对应于下面“改写字/新改写字 (Description #/New Description)”文本区域中的对应内容。
改写符号 (Rewrite char):
假设你的网志中出现一个单词“serendipity*”,你希望对“serendipity”这个单词重写,而希望其后面“*”所含的内容被自动去处掉,那么把“*”所对应的字符填在此处(“*”指代的可能是多个字符)。
改写名称/新改写名称 (Title #/New Title):
要被改写的内容。
改写字/新改写字 (Description #/New Description):
改写后的内容。
文章主内容:
对文章主内容中出现的上述关键字进行重写、替换。如果你不懂这是什么意思,选“是”。
文章副内容:
对文章副内容中出现的上述关键字进行重写、替换。如果你不懂这是什么意思,选“是”。
回复:
对文章回复中出现的上述关键字进行重写、替换。如果你不懂这是什么意思,选“是”。
HTML 信息:
对文本块(一般指侧栏插件产生的文本块)中出现的上述关键字进行重写、替换。如果你不懂这是什么意思,选“是”。
举例一
我们打算给文字网志中所有的关键字“deminy”添加一个HTML链接到http://www.deminy.net这个网站。HTML中,链接一般是这么表示的:<a href="http://www.deminy.net">deminy</a>。如果在网志正文中,我们只写了deminy这个关键字,而没有加上相应的HTML链接,那么我们可以通过这个“内容重写”插件重写相关的关键字以添加链接。方法如下:
改写字符 (Rewrite string):<a href="{to}">{from}</a>
改写名称/新改写名称 (Title #/New Title):deminy
改写字/新改写字 (Description #/New Description):http://www.deminy.net
举例二
我们打算给文字网志中所有的关键字“RSS”添加一个全称说明“Rich Site Summary,网站内容聚合”。XHTML中,标签acronym是可以用来标记、解释缩写词的。那么,我们可以通过这个“内容重写”插件重写相关的关键字以添加对缩写词的全称说明。也就是:
原文:RSS;现在:RSS。
方法如下:
改写字符 (Rewrite string):<acronym title="{to}">{from}</acronym>
改写名称/新改写名称 (Title #/New Title):RSS
改写字/新改写字 (Description #/New Description):Rich Site Summary,网站内容聚合
举例三
我们打算给文字网志中所有的关键字“emails”添加一个全称说明“电子邮件”,同时要在网页上去除掉最后一个多余的“s”字符。也就是:
原文:emails;现在:email。
方法如下:
改写字符 (Rewrite string):<acronym title="{to}">{from}</acronym>
改写符号 (Rewrite char):s
改写名称/新改写名称 (Title #/New Title):emails
改写字/新改写字 (Description #/New Description):电子邮件
特别提醒
1. 在当前版本的serendipity(v1.1之前)中,该插件可能仅对文本中最后一行之前出现的关键字产生效果。
2. 该插件可重复安装。
3. 用户可考虑使用另外一个类似的插件:Tooltips(提醒工具)。
[补充说明1] 如欲浏览更多关于Serendipity的使用、维护信息,请参考《网志程序Serendipity中文维护个人文集》一文。2007-07-15 14:23:19
外挂名称 (Plugin-Title):
该插件在你网志的插件列表中的可识别名称。此处可为任意可识别标题,种族歧视内容除外。
改写字符 (Rewrite string):
将要重写的内容的模版。这里需要使用特殊标记“{from}”和“{to}”。前者({from})对应于下面“改写名称/新改写名称 (Title #/New Title)”文本区域中的内容,后者({to})对应于下面“改写字/新改写字 (Description #/New Description)”文本区域中的对应内容。
改写符号 (Rewrite char):
假设你的网志中出现一个单词“serendipity*”,你希望对“serendipity”这个单词重写,而希望其后面“*”所含的内容被自动去处掉,那么把“*”所对应的字符填在此处(“*”指代的可能是多个字符)。
改写名称/新改写名称 (Title #/New Title):
要被改写的内容。
改写字/新改写字 (Description #/New Description):
改写后的内容。
文章主内容:
对文章主内容中出现的上述关键字进行重写、替换。如果你不懂这是什么意思,选“是”。
文章副内容:
对文章副内容中出现的上述关键字进行重写、替换。如果你不懂这是什么意思,选“是”。
回复:
对文章回复中出现的上述关键字进行重写、替换。如果你不懂这是什么意思,选“是”。
HTML 信息:
对文本块(一般指侧栏插件产生的文本块)中出现的上述关键字进行重写、替换。如果你不懂这是什么意思,选“是”。
举例一
我们打算给文字网志中所有的关键字“deminy”添加一个HTML链接到http://www.deminy.net这个网站。HTML中,链接一般是这么表示的:<a href="http://www.deminy.net">deminy</a>。如果在网志正文中,我们只写了deminy这个关键字,而没有加上相应的HTML链接,那么我们可以通过这个“内容重写”插件重写相关的关键字以添加链接。方法如下:
改写字符 (Rewrite string):<a href="{to}">{from}</a>
改写名称/新改写名称 (Title #/New Title):deminy
改写字/新改写字 (Description #/New Description):http://www.deminy.net
举例二
我们打算给文字网志中所有的关键字“RSS”添加一个全称说明“Rich Site Summary,网站内容聚合”。XHTML中,标签acronym是可以用来标记、解释缩写词的。那么,我们可以通过这个“内容重写”插件重写相关的关键字以添加对缩写词的全称说明。也就是:
原文:RSS;现在:RSS。
方法如下:
改写字符 (Rewrite string):<acronym title="{to}">{from}</acronym>
改写名称/新改写名称 (Title #/New Title):RSS
改写字/新改写字 (Description #/New Description):Rich Site Summary,网站内容聚合
举例三
我们打算给文字网志中所有的关键字“emails”添加一个全称说明“电子邮件”,同时要在网页上去除掉最后一个多余的“s”字符。也就是:
原文:emails;现在:email。
方法如下:
改写字符 (Rewrite string):<acronym title="{to}">{from}</acronym>
改写符号 (Rewrite char):s
改写名称/新改写名称 (Title #/New Title):emails
改写字/新改写字 (Description #/New Description):电子邮件
特别提醒
1. 在当前版本的serendipity(v1.1之前)中,该插件可能仅对文本中最后一行之前出现的关键字产生效果。
2. 该插件可重复安装。
3. 用户可考虑使用另外一个类似的插件:Tooltips(提醒工具)。
[补充说明1] 如欲浏览更多关于Serendipity的使用、维护信息,请参考《网志程序Serendipity中文维护个人文集》一文。2007-07-15 14:23:19
类别:
Serendipity中文乱码解决方案 (3)
本文讨论的是如何消除内置插件“serendipity_archives_plugin”和侧栏插件“serendipity_plugin_comments”在页面显示的时候出现乱码的问题。
本文适用于Serendipity v0.8.x到v1.0。
乱码可能只在特定的情况下出现。
出现乱码的可能原因有几个,例如系统不支持多字节函数、使用了wordwrap等不支持多字节的函数等。
以下用Serendipity v1.0代码举例说明。该系统采用了简体中文(utf-8)编码。
1. 解决内置插件“serendipity_archives_plugin”的乱码
在文件“./include/lang.inc.php”中,函数serendipity_mb()里,第63行代码原先为:
return mb_strtoupper(mb_substr($args[1], 0, 1)) . mb_substr($args[1], 1);
将其修改为:
return mb_strtoupper(mb_substr($args[1], 0, 1, mb_detect_encoding($args[1])), mb_detect_encoding($args[1])) . mb_substr($args[1], 1, mb_strlen($args[1], mb_detect_encoding($args[1])), mb_detect_encoding($args[1]));
这其实可能是多此一举的做法,因为一般默认相关的多字节函数会自动选取默认编码,不需要明确写出来。但是不知何处有bug(也许是PHP的,也许是Serendipity的,也许是我所作的配置方面的),使得这里必须明确说明所采用的编码。
2. 解决侧栏插件“serendipity_plugin_comments”的乱码
在文件“serendipity_plugin_comments.php”中,函数generate_content(&$title)里,从153行到202行左右,做2个工作:
2.1 将“$serendipity['lang'] == "ja"”改成“$serendipity['lang'] == "cn"”;1
2.2 将mb_strimwidth和mb_strlen等多字节函数全部加上编码参数。例如,
原先:mb_strlen( $comment)
现在:mb_strlen( $comment, mb_detect_encoding($comment))
[注1] 看上去这段像小日本写的代码,只顾自己,不顾别人。
[补充说明1] 本文的方法可能不是治本的方法。该系统太大,因此调试困难。
[补充说明2] 我昨天已向Serendipity官方提出这个bug及其解决方法。其技术人员已将相关代码修改,因此该bug将不会出现在下一个版本的Serendipity中。2006-06-23 10:03:44
[补充说明3] 如欲浏览更多关于Serendipity的使用、维护信息,请参考《网志程序Serendipity中文维护个人文集》一文。2007-07-15 14:23:19
本文适用于Serendipity v0.8.x到v1.0。
乱码可能只在特定的情况下出现。
出现乱码的可能原因有几个,例如系统不支持多字节函数、使用了wordwrap等不支持多字节的函数等。
以下用Serendipity v1.0代码举例说明。该系统采用了简体中文(utf-8)编码。
1. 解决内置插件“serendipity_archives_plugin”的乱码
在文件“./include/lang.inc.php”中,函数serendipity_mb()里,第63行代码原先为:
return mb_strtoupper(mb_substr($args[1], 0, 1)) . mb_substr($args[1], 1);
将其修改为:
return mb_strtoupper(mb_substr($args[1], 0, 1, mb_detect_encoding($args[1])), mb_detect_encoding($args[1])) . mb_substr($args[1], 1, mb_strlen($args[1], mb_detect_encoding($args[1])), mb_detect_encoding($args[1]));
这其实可能是多此一举的做法,因为一般默认相关的多字节函数会自动选取默认编码,不需要明确写出来。但是不知何处有bug(也许是PHP的,也许是Serendipity的,也许是我所作的配置方面的),使得这里必须明确说明所采用的编码。
2. 解决侧栏插件“serendipity_plugin_comments”的乱码
在文件“serendipity_plugin_comments.php”中,函数generate_content(&$title)里,从153行到202行左右,做2个工作:
2.1 将“$serendipity['lang'] == "ja"”改成“$serendipity['lang'] == "cn"”;1
2.2 将mb_strimwidth和mb_strlen等多字节函数全部加上编码参数。例如,
原先:mb_strlen( $comment)
现在:mb_strlen( $comment, mb_detect_encoding($comment))
[注1] 看上去这段像小日本写的代码,只顾自己,不顾别人。
[补充说明1] 本文的方法可能不是治本的方法。该系统太大,因此调试困难。
[补充说明2] 我昨天已向Serendipity官方提出这个bug及其解决方法。其技术人员已将相关代码修改,因此该bug将不会出现在下一个版本的Serendipity中。2006-06-23 10:03:44
[补充说明3] 如欲浏览更多关于Serendipity的使用、维护信息,请参考《网志程序Serendipity中文维护个人文集》一文。2007-07-15 14:23:19
类别:
在网上搜索信息 (2) —— 用Whois搜索个人信息
[引言] 本系列文字都是顺手举例说明,行文并不一定规范。本系列文字所探讨的技术或技巧,均遵循合理的原则,不出格、不越轨、不下三烂。
 前两天,在MyCUST看到一个帖子,说的是一位女校友开了个叫“Hey,Sunny!”的网志(博客),用的还是个顶级域名(.com的)。咱自然过去转了转。
前两天,在MyCUST看到一个帖子,说的是一位女校友开了个叫“Hey,Sunny!”的网志(博客),用的还是个顶级域名(.com的)。咱自然过去转了转。
“可恼”的是,虽然咱对Serendipity网志系统推崇不已,该女校友用的网志系统却是WordPress(Serendipity的大敌),而且还对WordPress推崇不已。当然,WordPress的确功能相当强大,而且这位女校友也是相当的伶俐,居然把这个WordPress用得还比较得心应手。
今天再访问一下该网志,嘿嘿,发现这位女校友当真是有趣,居然“模仿”起本站的“更新记录”栏目,做了个“建站記錄”栏目来记录她的网站建设过程。这倒让我想去查查她这个网站的建站历史了。
好了,言归正传。说说我怎么来搜她的建站历史(和个人信息)的。
当然,在她的网址上有一个“About Sunny”网页,已经提供了相当丰富的个人信息。你还可以去翻MyCUST的论坛帖子、用搜索引擎等等去获取更多的信息。这些老套的手法咱已经在“举例说明如何在网上挖掘一个人的信息”一文中有所提及,但该文中所述的搜索方法并不(很)符合咱这次搜索目的的需要。
本文说的是另外一个比较有效的方法:用whois。
右上图就是对该网站域名使用whois搜索后得到的结果,嘿嘿,还比较有效吧(具体就不废话解释了)。关于whois具体信息,可以在“百度知道”获得。
你也可以用同样的手法通过whois搜索deminy的个人信息(结果如右下图所示)。
这种搜索手法主要只对拥有独立域名的个人(或团体等)有效,但并不一定每个拥有独立域名的个体就会公布相应的个体信息的。
[补充说明1] “在网上搜索信息 (1)”可以认为是“举例说明如何在网上挖掘一个人的信息”一文。
前两天,在MyCUST看到一个帖子,说的是一位女校友开了个叫“Hey,Sunny!”的网志(博客),用的还是个顶级域名(.com的)。咱自然过去转了转。“可恼”的是,虽然咱对Serendipity网志系统推崇不已,该女校友用的网志系统却是WordPress(Serendipity的大敌),而且还对WordPress推崇不已。当然,WordPress的确功能相当强大,而且这位女校友也是相当的伶俐,居然把这个WordPress用得还比较得心应手。
今天再访问一下该网志,嘿嘿,发现这位女校友当真是有趣,居然“模仿”起本站的“更新记录”栏目,做了个“建站記錄”栏目来记录她的网站建设过程。这倒让我想去查查她这个网站的建站历史了。
好了,言归正传。说说我怎么来搜她的建站历史(和个人信息)的。
当然,在她的网址上有一个“About Sunny”网页,已经提供了相当丰富的个人信息。你还可以去翻MyCUST的论坛帖子、用搜索引擎等等去获取更多的信息。这些老套的手法咱已经在“举例说明如何在网上挖掘一个人的信息”一文中有所提及,但该文中所述的搜索方法并不(很)符合咱这次搜索目的的需要。
本文说的是另外一个比较有效的方法:用whois。
右上图就是对该网站域名使用whois搜索后得到的结果,嘿嘿,还比较有效吧(具体就不废话解释了)。关于whois具体信息,可以在“百度知道”获得。
你也可以用同样的手法通过whois搜索deminy的个人信息(结果如右下图所示)。
这种搜索手法主要只对拥有独立域名的个人(或团体等)有效,但并不一定每个拥有独立域名的个体就会公布相应的个体信息的。
[补充说明1] “在网上搜索信息 (1)”可以认为是“举例说明如何在网上挖掘一个人的信息”一文。
类别:
如何生成网志信息统计图形
前几天从keso的网志链接过去后看到一篇文字“Keso博客发布时间的统计分析”,图形画得比较有意思。我考虑了一下,那个统计图(至少)有两种实现方式:普通用户的方式和程序员的方式。1
(以下的讨论以本站网志和本站网志使用的Serendipity系统为例)
一、普通用户的方式:Excel生成
首先,将网站的网志信息导出来。例如,Serendipity网志系统就有“文字导出”(Export entries)的功能,能够把全部文字导出到RSS中(XML格式)。
除了xls文件格式外,Microsoft Excel还能够读入多种文件格式,例如csv格式和XML格式。那么,就用Excel打开这个XML导出文件。2
把相关的信息在Excel中稍作处理,然后使用Excel的画图功能画图。在这个过程中,(可能)需要使用一些Excel的相关函数处理数据,例如datevalue()、left()等。
 这个方法适用于大多数(颇为)熟悉Excel使用的用户,不需要什么编程操作。右图就是使用此方法制作的本站2003年7月到现在所有的网志文字发布时间的统计信息。3
这个方法适用于大多数(颇为)熟悉Excel使用的用户,不需要什么编程操作。右图就是使用此方法制作的本站2003年7月到现在所有的网志文字发布时间的统计信息。3
二、程序员的方式:PHP生成
显然,用PHP画图需要用到用于画图的GD库,还需要相应的字体支持。
在经典的PHP函数库网站phpclasses搜索,很难发现让人满意的第三方图形类库用于画图。但其实,PHP自带的PEAR函数库就具有极强的画图功能,不需要另外找第三方函数库。
我以往极少采用PEAR写程序。前几天翻了翻,好像PEAR提供的具体使用文档很少。不管怎样,还是把如何用PEAR画图的方法简单讲一下(,免得自己以后忘了)。4
1. (至少)需要用到PEAR中的三个Image库:Image_Graph,Image_Canvas,Image_Color。下载它们并放到适当位置。
2. (一般来讲)要把PEAR所在位置加到php.ini所定义的incude_path中。
3. 需要一些TrueType的字体。“PEAR/Image/Canvas/Fonts/fontmap.txt”这个文件定义了相关的字体(文件)名字。(从网上或服务器上)找到这些字体文件,把这些字体文件放到系统某个位置。
4. 在“PEAR/Image/Canvas.php”文件中,定义常量“IMAGE_CANVAS_SYSTEM_FONT_PATH”。此常量用来指定字体文件所在位置。
 5. 参考“PEAR/Graph/docs”和“Graph/tests”下的多个画图的例子,挺简单的。这里就给两个和本文提到的离散图相关的例子(见右图):
5. 参考“PEAR/Graph/docs”和“Graph/tests”下的多个画图的例子,挺简单的。这里就给两个和本文提到的离散图相关的例子(见右图):
5.1 “PEAR/Graph/docs/examples/double_category_axis.php”。
5.2 “PEAR/Graph/docs/examples/plot_scatter.php”。
在Serendipity中,可以使用方法二开发相关的图形统计插件。Deminy觉得自己写这个太浪费时间了,就免了。相信以后肯定会有人写的。
[注1] 上面提到的文章的作者使用的是一个叫做Swiff Chart软件制作统计图。
[注2] 如果你直接用Excel打开该XML文件困难的话,可能是因为缺乏必要的XML Schema信息。这时候,综合使用Excel的mapping功能,便可以将XML中的指定数据(pubDate)导入。
[注3] 以后有时间的话我会做具体数据的具体分析。
[注4] 此处相关代码和实现方式测试于3月24日下午。
(以下的讨论以本站网志和本站网志使用的Serendipity系统为例)
一、普通用户的方式:Excel生成
首先,将网站的网志信息导出来。例如,Serendipity网志系统就有“文字导出”(Export entries)的功能,能够把全部文字导出到RSS中(XML格式)。
除了xls文件格式外,Microsoft Excel还能够读入多种文件格式,例如csv格式和XML格式。那么,就用Excel打开这个XML导出文件。2
把相关的信息在Excel中稍作处理,然后使用Excel的画图功能画图。在这个过程中,(可能)需要使用一些Excel的相关函数处理数据,例如datevalue()、left()等。
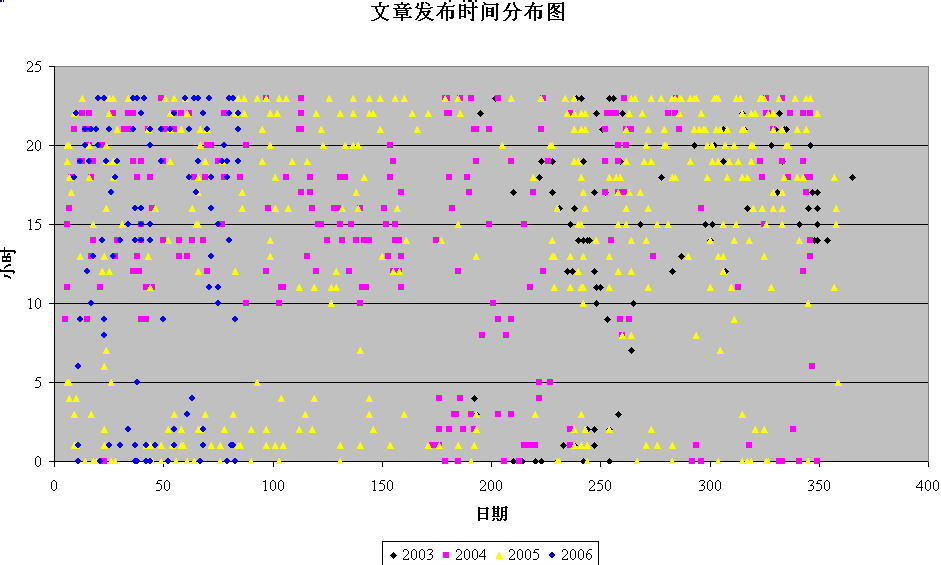 这个方法适用于大多数(颇为)熟悉Excel使用的用户,不需要什么编程操作。右图就是使用此方法制作的本站2003年7月到现在所有的网志文字发布时间的统计信息。3
这个方法适用于大多数(颇为)熟悉Excel使用的用户,不需要什么编程操作。右图就是使用此方法制作的本站2003年7月到现在所有的网志文字发布时间的统计信息。3二、程序员的方式:PHP生成
显然,用PHP画图需要用到用于画图的GD库,还需要相应的字体支持。
在经典的PHP函数库网站phpclasses搜索,很难发现让人满意的第三方图形类库用于画图。但其实,PHP自带的PEAR函数库就具有极强的画图功能,不需要另外找第三方函数库。
我以往极少采用PEAR写程序。前几天翻了翻,好像PEAR提供的具体使用文档很少。不管怎样,还是把如何用PEAR画图的方法简单讲一下(,免得自己以后忘了)。4
1. (至少)需要用到PEAR中的三个Image库:Image_Graph,Image_Canvas,Image_Color。下载它们并放到适当位置。
2. (一般来讲)要把PEAR所在位置加到php.ini所定义的incude_path中。
3. 需要一些TrueType的字体。“PEAR/Image/Canvas/Fonts/fontmap.txt”这个文件定义了相关的字体(文件)名字。(从网上或服务器上)找到这些字体文件,把这些字体文件放到系统某个位置。
4. 在“PEAR/Image/Canvas.php”文件中,定义常量“IMAGE_CANVAS_SYSTEM_FONT_PATH”。此常量用来指定字体文件所在位置。
 5. 参考“PEAR/Graph/docs”和“Graph/tests”下的多个画图的例子,挺简单的。这里就给两个和本文提到的离散图相关的例子(见右图):
5. 参考“PEAR/Graph/docs”和“Graph/tests”下的多个画图的例子,挺简单的。这里就给两个和本文提到的离散图相关的例子(见右图):5.1 “PEAR/Graph/docs/examples/double_category_axis.php”。
5.2 “PEAR/Graph/docs/examples/plot_scatter.php”。
在Serendipity中,可以使用方法二开发相关的图形统计插件。Deminy觉得自己写这个太浪费时间了,就免了。相信以后肯定会有人写的。
[注1] 上面提到的文章的作者使用的是一个叫做Swiff Chart软件制作统计图。
[注2] 如果你直接用Excel打开该XML文件困难的话,可能是因为缺乏必要的XML Schema信息。这时候,综合使用Excel的mapping功能,便可以将XML中的指定数据(pubDate)导入。
[注3] 以后有时间的话我会做具体数据的具体分析。
[注4] 此处相关代码和实现方式测试于3月24日下午。
